
はじめに
Cloud Pratica Advent Calendar 2025の投稿です。
2025年の初めにCloud Praticaに入会しました。各章で学びが生きた点について触れています。
(CP課題進捗 1/3 程度の時点での学びです。来年はもう少し頑張ります)
エンジニア歴も早いもので3年となりました。
2025年はAWSエンジニア2年目として、設計フェーズを任せていただくことも増え、技術的に手応えのあるタスクに携わることができました。
特に印象に残ったタスクについて、振り返りとしてアウトプットしたいと思います。
構成図は伝えたい部分を重点的に補足し、意図的に抽象化している点があります。
また、AWS公式情報に限り引用してます。
技術記事は初めて書くのでわかりづらい点もあるかと思いますが、振り返り記事ということでご容赦ください。
ちなみに以下の構成となってます。興味ある章だけでも読んでいただけると嬉しいです!
- 1章〜4章:インフラ設計(ネットワーク中心)
- 5章〜8章:運用改善
- 9章:コスト改善
1. AWS 閉域環境におけるネットワーク設計:VPCエンドポイント
閉域環境におけるネットワーク設計と検証を行いました。
今回のケースの閉域環境の定義は、AWSネットワークにおいてインターネットに接続しない環境とします。
よって、パブリックサブネット、Internet Gateway、NAT Gateway は存在しません。
ただし、既存のVPCとの通信が必須とされる要件でした。
ここでは「VPCエンドポイント設計の留意点」と「VPCエンドポイントのセキュリティグループ設計」の2点に絞って記載します。
VPCエンドポイント設計の留意点
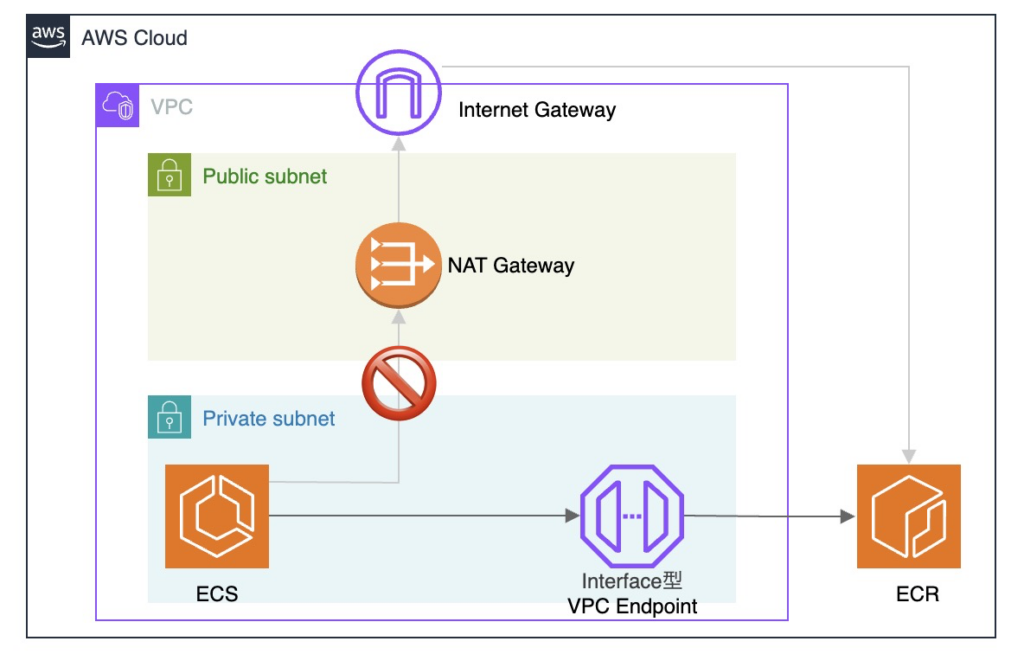
例として、ECS で ECR から Docker イメージを Pull する時の構成を抜粋して記載します。
まず、閉域の構成では、インターネットと通信することができません。
よって、各VPCエンドポイント経由でAWS サービスに到達させる必要があります。
1つのAWSサービスに対して、用途ごとに複数のVPCエンドポイントが存在し、
内部的に他サービスの API を利用する場合があることは注意すべきポイントです。
代表的なVPCエンドポイントを抜粋します。
最初に、Gateway型 VPCエンドポイントです。
S3 用とDynamoDB 用があります。
ECR のイメージ実体は S3 を利用しているため、ECR を閉域で使う場合は S3 の Gateway型 VPCエンドポイントが必要になります。
時間課金やデータ処理料金が発生せず、ルートテーブル設定をすれば使えます。
これは閉域環境問わず、一般的に構築が推奨されるリソースだと思います。
| 主な用途 | サービス名 | 補足 |
|---|---|---|
| S3 へのアクセス(ECR 実体含む) | com.amazonaws.ap-northeast-1.s3 | ECR 利用時に実質必須、Gateway 型 |
| DynamoDB へのアクセス | com.amazonaws.ap-northeast-1.dynamodb | DynamoDB 利用時、 Gateway 型 |
次に、Interface型 VPCエンドポイントです。
VPC 内のサブネットに ENI を構築します。
以下に代表的なリソースをリストします。
| 主な用途 | サービス名 | 補足 |
|---|---|---|
| CloudWatch Logs へログ送信 | com.amazonaws.ap-northeast-1.logs | ECS / EC2 / Fluent Bit 等からのログ送信 |
| CloudWatch メトリクス送信(Container Insights / カスタム) | com.amazonaws.ap-northeast-1.monitoring | PutMetricData API |
| ENI 作成・削除など EC2 API 利用 | com.amazonaws.ap-northeast-1.ec2 | EC2 / Lambda(VPC) / ECS(EC2起動タイプ)が内部的に使用 |
| ECR 管理 API(認証トークン取得など) | com.amazonaws.ap-northeast-1.ecr.api | ECR 利用時 |
| Docker Registry API(ECR イメージ取得) | com.amazonaws.ap-northeast-1.ecr.dkr | ECR 利用時 |
| SSM API(Parameter Store / ECS Exec) | com.amazonaws.ap-northeast-1.ssm | 環境変数取得、SSM Session Manager、ECS Exec |
| SSM Session Manager 通信(ECS Exec) | com.amazonaws.ap-northeast-1.ssmmessages | SSM Session Manager、ECS Exec |
このように各サービスの用途ごとにVPCエンドポイントを構築し、必要な通信を明確にする必要がある点は、NAT Gateway 経由の通信と大きく異なる点です。
今回は閉域環境のため、VPCエンドポイントが必須のケースです。
一方、設計当初は NAT Gateway も構築する想定だったため、コストの観点でも深掘りしました。
Interface型 VPCエンドポイントと NAT Gateway の料金を比較します。
東京リージョンにおける主な料金は以下の通りです。
| 項目 | NAT Gateway | Interface型 VPCエンドポイント |
|---|---|---|
| 時間課金 | 約 0.062 USD / 時間(1 AZ あたり) | 約 0.014 USD / 時間 / エンドポイント(1 AZ あたり) |
| データ処理料金 | 約 0.062 USD / GB | 約 0.01 USD / GB(最初の 1 PB) |
| 月 1 AZ 稼働コスト(時間課金 × 730h) | 約 45.26 USD | 約 10.22 USD |
| 通信経路 | インターネット経由 | AWS 内部ネットワーク |
実際には、2AZ 以上での冗長化は実質必須であり、VPCエンドポイントは複数必要です。
ここでは、NAT Gateway は2台、VPCエンドポイントは10個 * 2AZ = 20個で計算してみます。
また、データ処理料金は損益分岐点付近で比較しています。
| 項目 | NAT Gateway(2台) | Interface型 VPCエンドポイント(20個) |
|---|---|---|
| 構成 | 0.062 USD / 時間 × 2 台 | 0.014 USD / 時間 × 20 個 |
| 月間時間課金 | 45.26 × 2 = 90.52 USD | 10.22 × 20 = 204.40 USD |
| 月 1000 GB データ処理 | 1000 × 0.062 = 62.00 USD | 1000 × 0.01 = 10.00 USD |
| 月 2000 GB データ処理 | 2000 × 0.062 = 124.00 USD | 2000 × 0.01 = 20.00 USD |
| 月 3000 GB データ処理 | 3000 × 0.062 = 186.00 USD | 3000 × 0.01 = 30.00 USD |
データ処理料金は、VPCエンドポイントの場合、 NAT Gateway の 約 1/6 です。
よって、データ処理量が増えれば増えるほど、コストメリットは大きくなります。
では、コストメリットが大きい場合は、VPCエンドポイントにした方が良いのでしょうか。
これもケースバイケースです。
特に、既に本番運用されている環境で、VPC エンドポイントを構築する場合は注意が必要です。
設計が不十分な状態で置き換えを行うと通信障害が発生する可能性が高く、構成や運用の複雑性も増加します。
よって、インフラに詳しい担当者がいない現場では、NAT Gateway 経由のまま運用を継続する判断も現実的です。
Interface 型 VPC エンドポイントを構築する場合、通常は Private DNS 名を有効化して利用します。
Private DNS を有効化すると、対応するAWSサービスへの通信は、自動的にVPCエンドポイント経由となります。
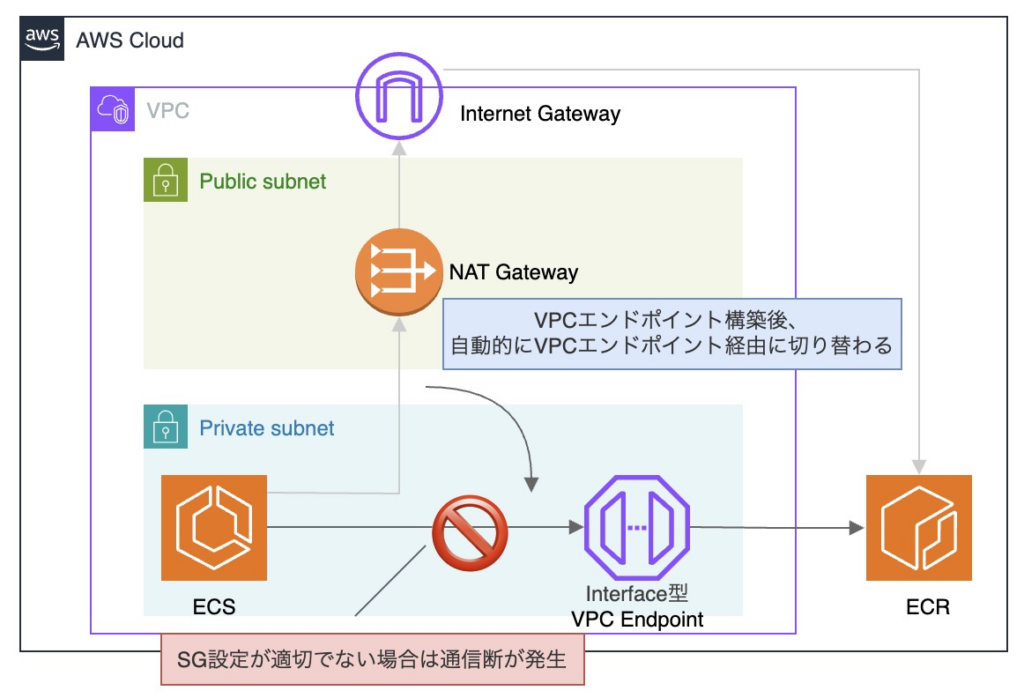
この設定は VPC 内のすべてのリソースの通信経路に影響があります。
よって、後述するセキュリティグループ設計において適切な許可設定が行われていない場合、
VPC エンドポイントで通信が遮断されることになります。
影響範囲を理解していれば、安易に構築できるものではないことがわかると思います。
今回は主にコストや影響範囲の観点で整理しましたが、実際の選定においては他にも様々な要素があります。
セキュリティとコストの両面から検討し、NAT Gateway と VPCエンドポイントを併用して使い分けて設計するケースも一般的です。
少し話が広がりましたが、NAT Gateway とVPC エンドポイントの選定は、ネットワーク設計において重要な判断ポイントの一つだと考えています。
セキュリティグループ設計
次に、具体的なセキュリティグループの許可設計について考えます。
送信元とVPCエンドポイントで、それぞれインバウンドとアウトバウンドを許可する必要があります。
特に今回はアウトバウンドを制限する要件があるため、厳密に許可を追加する必要がありました。
VPCエンドポイント同様に例として、ECS で ECR から Docker イメージを Pull する時の構成を抜粋して記載します。
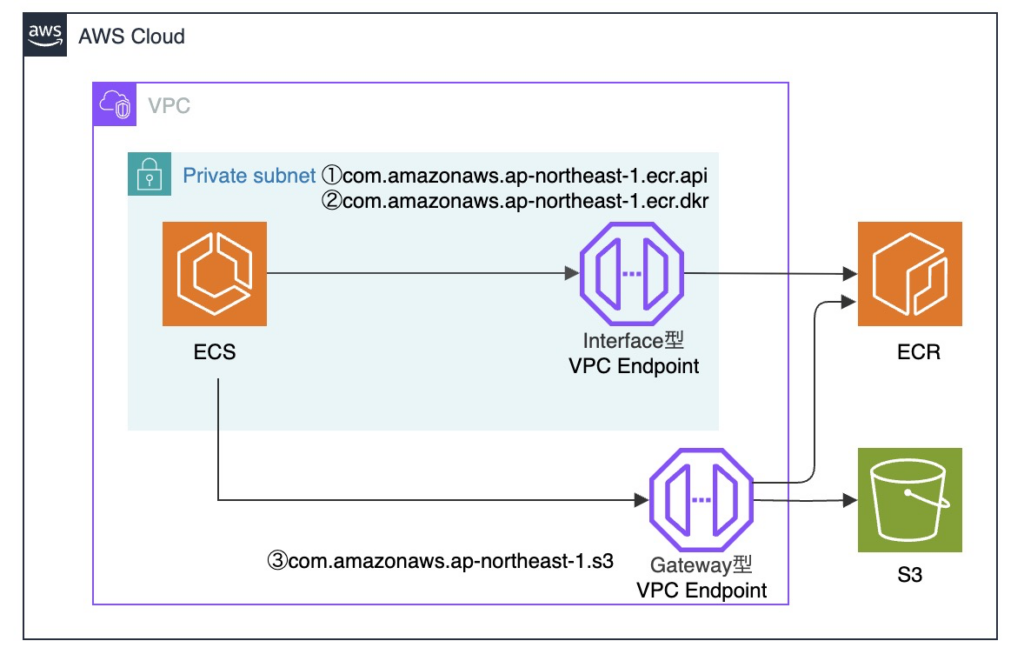
ここで、SGを関連付けできるのは、「VPCのサブネット内に作成される ENI を持つリソース」です。
上記構成図では、ECSタスクとInterface型VPCエンドポイントが該当し、それぞれSGを関連づける必要があります。
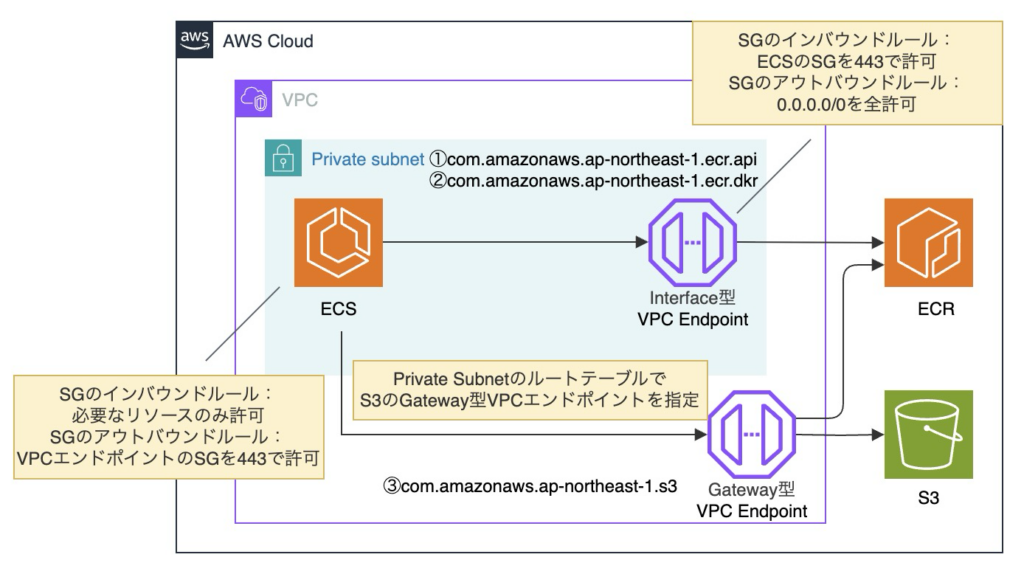
SG設計上の主な考慮点は、「ECS SGのアウトバウンド」および「VPC エンドポイント SGのインバウンド」です。
ECS SGのアウトバウンド
宛先をVPCエンドポイント(ENI)に限定し、ポート443で許可します。
許可方法としては、主に以下が考えられます。
| 許可方法 | 概要 | メリット | デメリット |
|---|---|---|---|
| VPC エンドポイント(ENI)のプライベート IP を許可 | VPC エンドポイントの ENI に割り当てられた個別 IP を許可する | 許可範囲を最小限に抑えられる | 再作成・増設時に IP 変更へ追従が必要となり、運用が複雑になりやすい |
| VPC エンドポイント(ENI)の SG を許可 | VPC エンドポイントの ENI に関連付けたセキュリティグループを許可する | 意図が明確で、構成変更時の追従がしやすい | エンドポイント数が増えると SG 管理が複雑化する |
| VPC エンドポイント(ENI)が存在するサブネット CIDR を許可 | VPC エンドポイントの ENI が属するサブネットの CIDR を許可する | 設定がシンプルで柔軟性が高い | 許可範囲が広くなり、意図しない通信も許可しやすい |
結論としてSGで許可する方針としました。
主観ですが、”許可の意図が明確かつ運用の柔軟性のバランスが取れた設計” として、美しいと思いました。
ただし、VPCエンドポイントごとにSGを作成する場合は、大量にSGが作成され、SG数だけ許可ルールを増やす必要があり、管理が複雑化します。
よって、VPCエンドポイント用のSGは、極力まとめて共通のSGとしました。
VPCエンドポイント SGのインバウンド
送信元をECS(ENI)に限定し、ポート443で許可します。
ECSのIPアドレスは動的であるため、許可送信元は SG もしくはサブネットCIDR が選択肢となります。
許可対象が多岐に渡るようであれば、サブネットCIDRで許可することを検討しますが、
今回は「ECSのアウトバウンド」同様にSGで許可する方針としました。
VPCエンドポイントのSGのアウトバウンド(参考)
なお、Interface 型 VPC エンドポイントに関連付けるSGのアウトバウンドについては、「アウトバウンド方向のルールを作成する必要はない」とAWS公式で明示されています。
注: インターフェイスエンドポイントに関連付けられているセキュリティグループのアウトバウンド方向でルールを作成する必要はありません。
https://repost.aws/ja/knowledge-center/security-network-acl-vpc-endpoint
よって、VPC エンドポイント(ENI)のSGにおけるアウトバウンドルールは、通信可否の判断に実質的な影響を与えません。
一方で、このような挙動は直感的に理解しづらく、運用時に混乱を招く可能性があります。
したがって、AWSデフォルト設定であるアウトバウンド全許可(0.0.0.0/0)を維持する方針としました。
以上を踏まえ、最終的に以下のような設定となりました。
▼CPからの学び
VPCエンドポイントと NAT Gateway の違いを深掘りさせていただき、指針も明確で実践的に設計ができました。
また、課題の中でNAT Gateway 代わりに構築した NATインスタンスは、停止起動も制御できるため、個人学習や簡単な検証に用途を限定した場合にはコスパ最高でした。調べて実装できるレベルだと思うので、NAT Gateway の課金に苦しんでいるすべてのAWS学習者に利用していただきたいです!
▼感想
「いったん全部 NAT Gateway で良くない?」という意見もわかりますが、VPCエンドポイントの理解は差がつく点だと思います。
今回は閉域なので NAT Gateway は完全に封印されましたが、比較してみると面白いですね。
「VPCエンドポイント経由の構成 × SGアウトバウンド制御」は、AWSのネットワーク周りの仕様や通信先を正確に理解する必要があり、設計レベルが1段階上がったと思います。制約と誓約によって力が手に入りました。
実際、オンプレの思想とは異なるので、AWSでSGのアウトバウンド制御までやってる現場は少ない印象です。
アウトバウンド制御は運用面でも事故りやすいし、インバウンドを厳密に絞ることの方が圧倒的に重要だと思います。(愚痴です笑)
2. AWS 閉域環境におけるネットワーク設計:PrivateLink 構成
続いて、AWS閉域環境における PrivateLink 構成について記載します。
OSI 参照モデルの L7 と L4 という表現を多用するので補足します。
アプリケーションレイヤ(L7):HTTPなどの通信内容を理解して処理する層
トランスポートレイヤ(L4):IPアドレスとポートを基に通信を中継する層
合わせて ALB と NLB についても簡潔に補足します。
Application Load Balancer(ALB):L7 で通信内容を解釈し、HTTPベースで柔軟なルーティングを行います。
Network Load Balancer(NLB):L4 で通信内容を解釈せず、IPとポートに基づいて通信を中継します。
PrivateLink 接続
セキュリティ要件上、VPC ピアリングではなく PrivateLink 接続 を採用しました。
PrivateLink 概要:
PivateLink は、接続先の各サービスに対応したVPC エンドポイントを介して、
インターネットを経由せずにセキュアにAWS サービスや外部サービスへ接続する仕組みです。
PrivateLink の最も王道な構成は、接続元 VPC にVPCエンドポイントを作成し、
接続先 VPC 側でエンドポイントサービスを介して NLB に接続するパターンです。
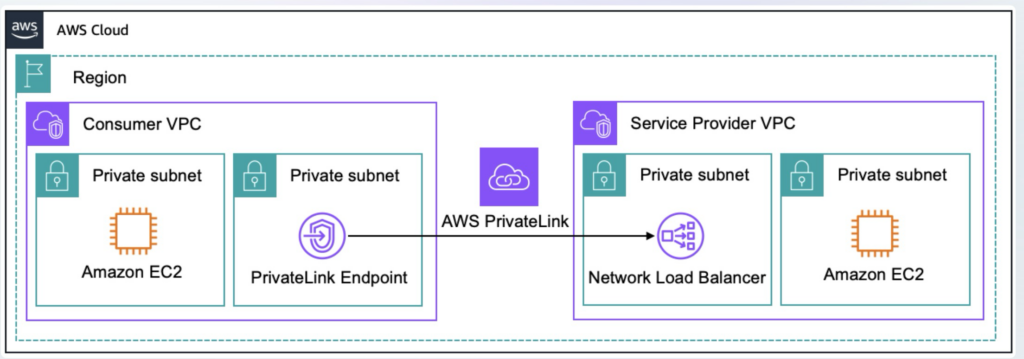
画像引用元:AWS PrivateLink
https://docs.aws.amazon.com/ja_jp/whitepapers/latest/aws-vpc-connectivity-options/aws-privatelink.html
また、接続先となる ECS は ALB などを介する L7 でのルーティングが求められていました。
そこで、以下の3パターンに分けて構成を検討しました。
- NLB → ALB → ECS 構成
- VPC Lattice 構成
- Resource Gateway → ALB → ECS 構成
※ VPC Lattice / Resource Gateway は内部的に PrivateLink を利用しており、
ここでは PrivateLink 相当の構成として整理しています。
NLB → ALB → ECS 構成
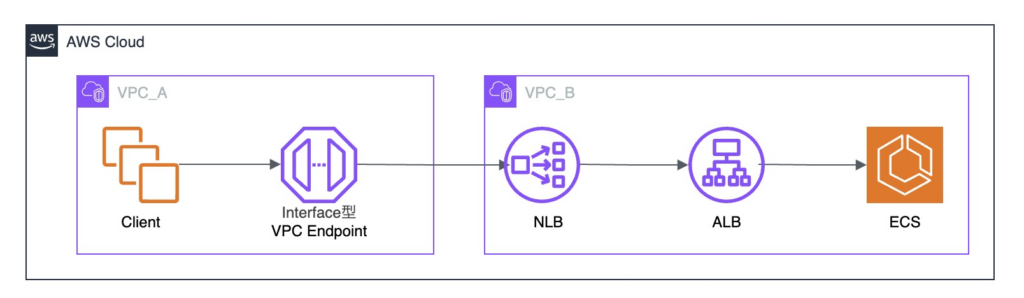
NLB → ALB → ECS 構成は、従来通りの代表的な構成です。
ALB は PrivateLink の直接のターゲットにできないため、NLB を経由する構成となります。
接続元 VPC にInterface型 VPCエンドポイントを作成し、対向 VPC 側の NLB で L4 の通信を受け、ALB で L7 のルーティングを実現します。
なお、構成図では省略していますが、対向側ではエンドポイントサービスの設定が必要です。
2021年9月時点で AWS 公式推奨パターンとされていました。
参考記事:Application Load Balancer-type Target Group for Network Load Balancer
https://aws.amazon.com/jp/blogs/networking-and-content-delivery/application-load-balancer-type-target-group-for-network-load-balancer
VPC Lattice 構成
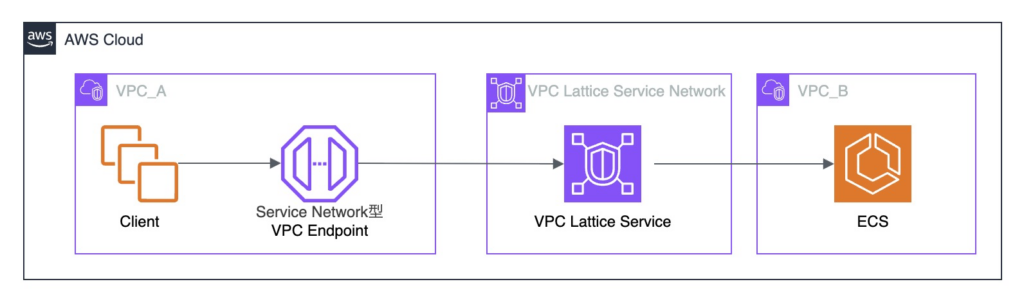
複数の接続先があるため、VPC Lattice の構成を検討しました。
2024年12月に VPC Lattice で L4 で接続で VPC 内のリソースへアクセス可能になり、選択の幅が広がりました。
VPC Lattice 概要:
VPC Lattice は、AWS が提供するサービスネットワークです。
VPC の外側で動作し、VPC をサービスネットワークに関連付けることでサービス間通信を実現します。
接続元VPC にService Network型VPCエンドポイントを作成します。
VPC Lattice について4パターン検討しました。
①Lattice(HTTPS=L7) → ALB → ECS
Lattice を HTTPS(L7)として利用する構成では、PrivateLink を利用できないため要件を満たしません。
②Lattice(TLS=L4) → ALB → ECS
Lattice を TLS(L4)として利用する構成では、ALB をターゲットとして指定できないため要件を満たしません。
(LatticeはL7でのみ、ALBをターゲット登録可能です)
また、ALBのIPを直接ターゲットに指定することで構成の実現自体は可能ですが、ALBのIPは動的であり、安定性に欠けるため適しません。
③Lattice(TLS=L4) → ECS
Lattice を TLS(L4)として利用し ECS に直接接続する構成では、L7 ルーティングが行えず(TLS はデフォルトルールのみ)、要件を満たしません。
④Lattice(TLS=L4)→ Resource Gateway → ALB → ECS
Resource ConfigurationでALB(Internal)のDNS名を名前解決できれば実現可能です。
ただし、接続元VPCから直接 Resource Gateway にアクセス可能なため、
後述する 「Resource Gateway → ALB → ECS」 構成 として VPC Lattice を意識しない構成として別途検討します。
結論として、PrivateLink では対向先はL4で通信を受ける必要がありますが、
VPC Lattice はALBをターゲットに指定できないので、今回の選定からは外れる結果になりました。
Resource Gateway → ALB → ECS 構成
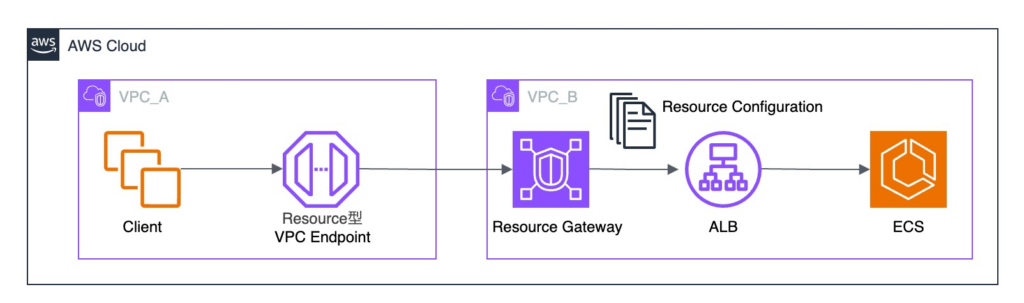
※ Resource Gateway は VPC Lattice のコンポーネントの一部ですが、本記事は PrivateLink 構成の比較を目的としており、
VPC Lattice の詳細を意識せずに構築できるため、詳細な構成要素は抽象化して表現しています。
VPC Latticeのパターンにも記載した Resource Gateway を使用する構成です。
Resource Gateway概要:
Resource Gateway は、VPC Lattice を内部的に利用した接続機能です。
PrivateLink 経由で他のVPC やサービスのリソースに安全に接続できます。
Resource Configurationでリソース(DNS 名)をターゲットに指定することで、
Resource Gatewayから通信が可能となります。
一方、Resource Configuration に指定できるドメイン名は、
AWS が提供するパブリック DNS サービスで名前解決できることが要件です。
内部 ALB に割り当てられる DNS 名は、インターネットへ到達可能ではありませんが、
AWS のパブリック DNS で解決可能という仕様のため、Resource Configuration のターゲットとして指定ができました。
実際に本構成で検証を行い、対向先の ECS まで疎通可能であることを確認しています。
NLB → ALB → ECS 構成と比較し、コスト面でメリットが大きい場合は採用する方針としました。
コスト比較
ここで、NLB および ALB は 2AZ 以上の選択が必須で、対向先の ECS も基本的に 1AZ で構成することは稀です。
よって、VPCエンドポイントも 2AZ 以上で作成することが実質必須です。
処理データ料金は、両方とも$0.01/GBで同等です。
また、NLB では、NLCU 料金、Resource Gateway では、リソース共有料金が発生しますが、今回はあまり差がつくような要件ではないため、考慮しないものとします。
よって、ここでは構成差分のある以下の1時間あたりの従量課金のみで比較しました。
・NLB → ALB → ECS 構成
Interface型 VPCエンドポイント:$0.014 * 2 = $0.028
NLB:$0.0243
合計:$0.028 + $0.0243 = $0.0523
・Resource Gateway → ALB → ECS 構成
Resource型 VPCエンドポイント:$0.028 * 2 = $0.056
結果として、コストはほとんど変わりませんでした。
以上から、既存の環境で実績がある「NLB→ALB→ECS 構成」を採用しました。
CPからの学び
CPで「L4とL7の違いを理解できればネットワーク力が1桁上がる!」というOSI 参照モデルについて実践的に説明されたドキュメントを読み、レイヤーに対する意識と解像度が上がりました。
元々なんとなく理解していたつもりでしたが、深掘りすることで自信を持って検証結果を説明できるようになりました。
Kubernetes の課題は未着手ですが、各チャプターと概要を見てネットワーク理解が確実に強化される確信を持ったので、今からめちゃくちゃ楽しみです。
▼感想
OSI参照モデルって「アプセトネデブ」みたいなゴロで最初覚えたりするじゃないですか。
当時はもはや一般教養的な感覚で、実務で何の役に立つんだろうぐらいに思ってましたが、
意識し始めると通信の解像度が上がって、明らかに理解に違いが出ますね。
見える世界がモノクロからカラーになったようで興奮します。
真面目な話、PrivateLink で実現可能な構成が増えていたことには驚きましたが、
比較的最新の技術である VPC Lattice や Resource Gateway の調査・検証ができて良かったです!
3. EC2 → ECS Fargate へのリプレイス
EC2 からECS Fargate にリプレイスを行いました。
リプレイスの主な目的は以下の通りです。
- 運用負荷の低減
- 開発の生産性向上
- スケーリングの柔軟性向上
- SSH 接続を廃止し、セキュリティ性向上
- 構成・設定の標準化(定義管理による再現性向上)
「リプレイス構成検討」と「向き先切り替え設計」の2点の設計に絞って記載します。
リプレイス構成検討
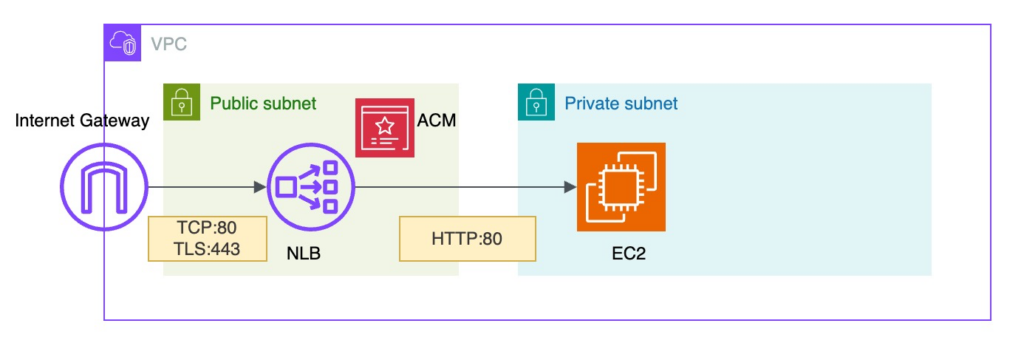
上記構成図は、一部を抜粋したリプレイス前の構成です。
NLB は TCP:80 および TLS:443 の両方で通信を受信し、
TLS:443 の通信は、NLB に TLS リスナーを設定することで NLB で終端し、EC2 へ HTTP:80 で転送します。
※ 終端:暗号化された通信を復号し、平文通信として扱い始める箇所
NLBの固定要件もあり、「NLB → EC2 構成」から「NLB → ECS 構成」へのリプレイスを当初は想定していました。
EC2 から ECS に置き換えるだけの構成のため、考慮すべき点を最小限に抑えられるためです。
しかし、Blue/Green デプロイ構成が必須要件であり、本番運用を安定して行うには、
トラフィックの段階的切替や切戻しを仕組みとして担保する必要もありました。
これを実現するためには、NLB のみの構成や ECS ネイティブの Blue/Green デプロイ ではトラフィック制御の柔軟性に限界があり、CodeDeploy を採用する必要があると判断しました。
また、トラフィック制御が ALB を前提としていることから、ALB を介した構成としました。
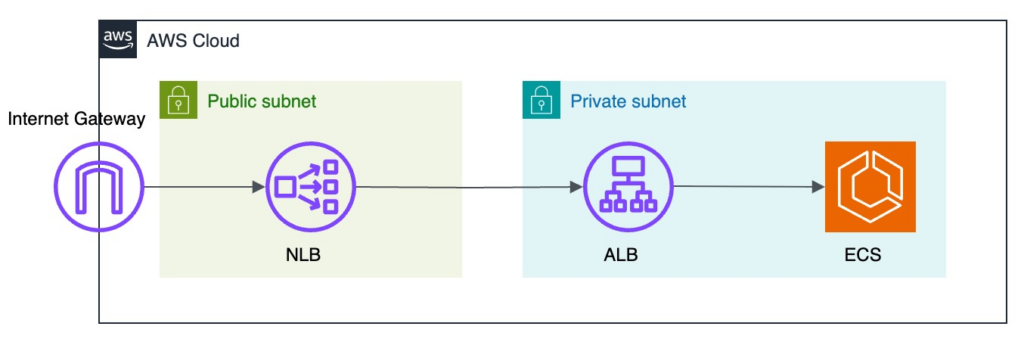
上記背景から、PrivateLink でも検討した「NLB → ALB → ECS」構成でリプレイス設計を進めました。
最初に、TLS(HTTPS)による暗号化通信の終端位置は ALB としました。
ALB で終端することで、L7 のルーティングやリダイレクト、証明書管理など、
外部からの HTTP/HTTPS アクセス制御を ALB 側に集約できるためです。
次に、Blue/Green デプロイに対応するため、本番用とテスト用でALBリスナーを分離しました。
本番用リスナーは 443、テスト用リスナーは 10443 を使用し、切替や疎通確認をポート単位で明確化します。
最後に、TLS 終端を ALB に寄せる方針としたため、NLB のリスナーは TCP とし、ALB の各リスナーへそのまま転送します。
NLB のポートは ALB と同一ポートで統一しています。
上記設計を構成図で表すと以下のようになります。
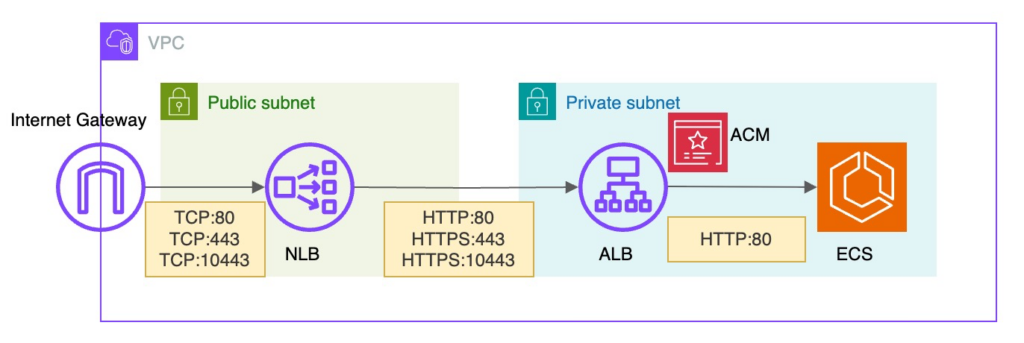
ロードバランサー周りの設定だけでも考慮すべき点は多く、リスナールール、セキュリティグループ、プロトコル、Target Group のヘルスチェック、ALBの負荷分散方式、証明書、SNI、セキュリティポリシー、など1つ1つ見落としがないように注意深く設計していきました。
向き先切り替え設計(Blue/Green デプロイ対応)
次の課題となったのは向き先切り替えです。
通信障害を発生させずに切り替える方法を検討しました。
優先度変更による切り替え方式
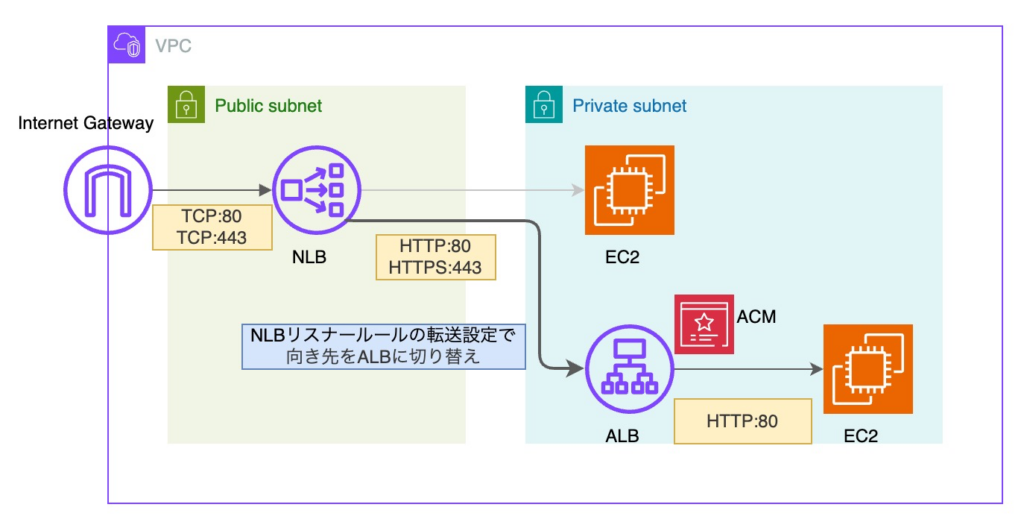
まず、ALB 経由で通信させるため、「NLB → EC2」構成から「NLB → ALB → EC2」構成へ変更する必要がありました。
「ALB → EC2」構成を事前に構築しておき、NLB の向き先を切り替える方針で進めています。
ポイントとしては、終端位置が NLB から ALB に変更されることです。
よって、このタイミングで NLBのリスナー も TLS から TCP に変更する必要がありました。
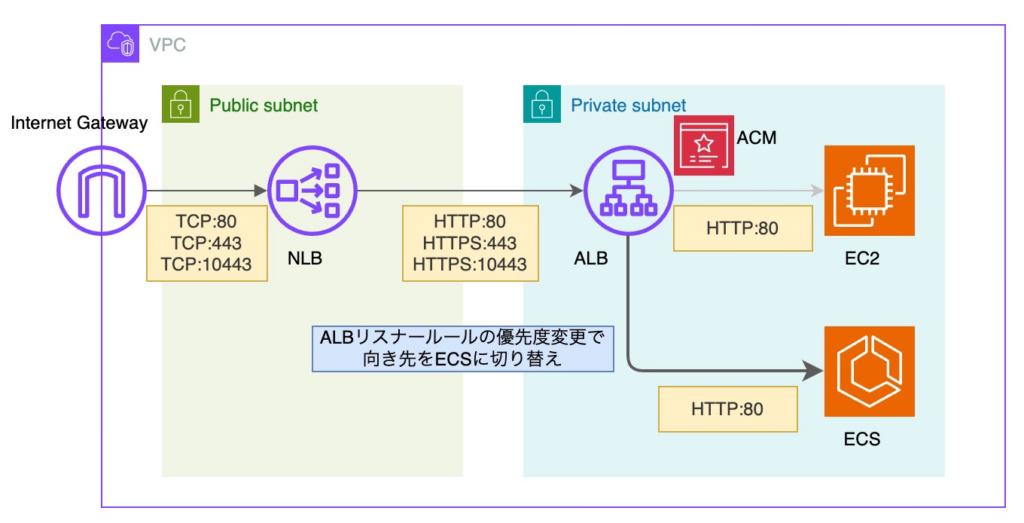
次に、NLB → ALB → ECS への切り替えです。
切り替えは ALB のリスナールールの優先度変更によって行う作戦でいきました。
また、NLB、ALB 共にテスト用リスナーを事前に構築しておきました。
ここで課題となったのは、ALB のリスナールール変更です。
NLB ではリスナールールはデフォルトルールのみ選択可能です。
よって、ALB リスナールールもデフォルトルールで転送する設定としていました。
しかし、デフォルトルールは優先度を変更できない仕様であることが判明しました。
そこで、「100%条件を満たす条件を指定し、EC2 および ECS へ転送するルール」をそれぞれ追加することで、優先度変更を可能としました。
ただし、ALB のリスナールール条件は 5つまでという制約があります。
また、Host数が多かったため、一般的な Host ヘッダー条件では対応できない状況でした。
そこで、アクセスログを確認し、実際に使用されている HTTPリクエストメソッドをすべて指定することで、
優先度変更による切り替えに対応しました。
| 優先度 | 条件(HTTP リクエストメソッド) | アクション |
|---|---|---|
| 10 | GET / POST / HEAD / OPTIONS | EC2 へ転送 |
| 20 | GET / POST / HEAD / OPTIONS | ECS へ転送 |
| デフォルト | - | EC2 へ転送 |
ポート80のリダイレクト処理
2つ目のポイントは、ポート80のリダイレクト処理です。
Blue/Green デプロイ時において HTTPS:443/10443 は自動で Target Group が切り替わります。
しかし、HTTP:80 は自動切替対象外のため、手動で Target Group を切り替えなければなりません。
これは通信が一時的に分離される点や運用負荷の点でも避けたい構成です。
以下は、Blue/Green デプロイのトラフィック切り替え後の挙動を示した図です。
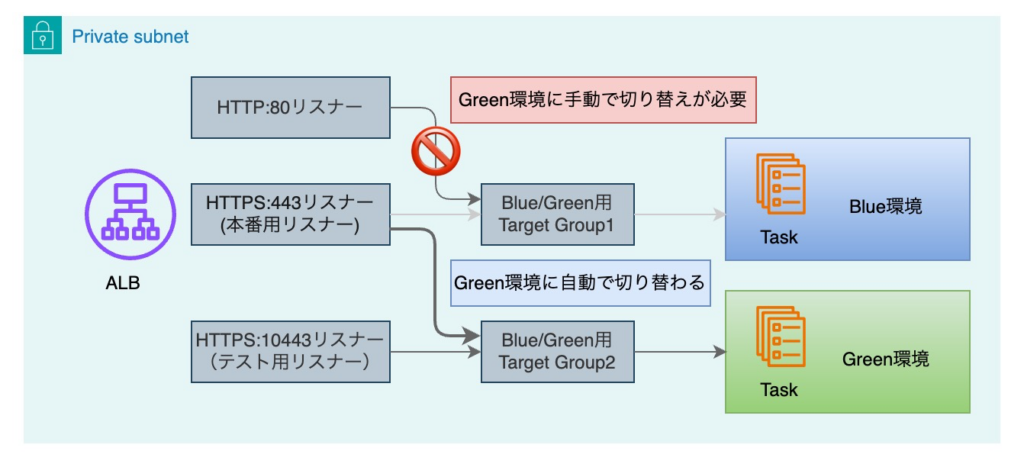
外部からの HTTP:80 通信自体は制御できないため、ポート80を残すことは必須でした。
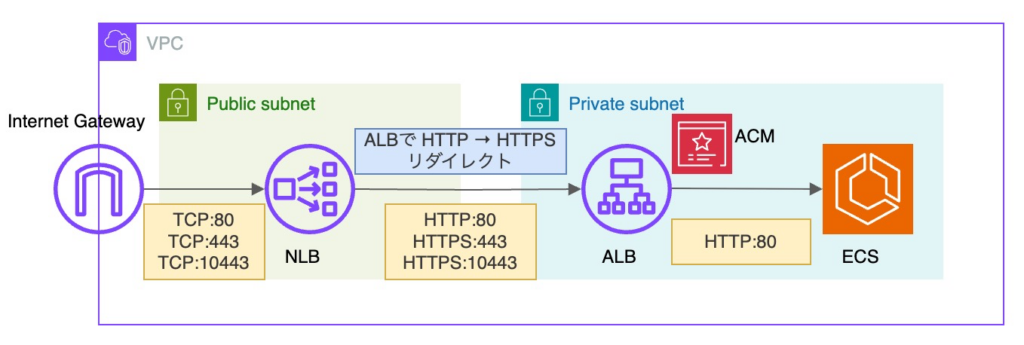
そこで、アプリ側と協議し、以下の方針で対応することにしました。
- アプリ側で HTTP:80 経由でアクセスされた場合でも問題が発生しないよう調整
- インフラ側で ALBリスナールールで HTTP:80 の通信を HTTPS:443 へリダイレクト
HTTP:80 をリダイレクト専用とすることで、Target Group の切り替えは考慮不要となります。
なお、リダイレクトレスポンス分の転送量は微増のため、負荷に影響はないと判断しました。
最終構成は以下の通りです。
構成図上はシンプルに見えますが、切り替え方法を含め、考慮する観点は多い設計でした。
▼CPからの学び
記事では割愛しましたが、今回の構成の中で SQS 受信データを元にリクエストを送る処理の実装がありました。
SQS による非同期処理の課題から、バックエンド側の背景を学んでいたため、ジョブ処理の流れを理解し、ログの確認、SQS の設定の妥当性の考慮などができました。
学びがなければ、依頼通りに構築することに留まり、インフラ設計への理解も浅かったと思います。
インフラ専任でもバックエンド側の理解の必要性を痛感しました。
▼感想
設定を1つでもミスると通信障害が発生するため、神経を使ったタスクでした。
実際、ALB の負荷分散方式や SNI の設定は、リリースが近くなったタイミングで気づきましたが、オンプレの設定を踏襲している背景などがあるとまさに地雷の山です。
石橋を叩いて、叩いて、橋が壊れないことを徹底的に疑い、周囲の安全確認までするぐらいの慎重さが試されるのがインフラエンジニアって感じです。もちろん最後は、えいやっ!で行くしかありません。
4. Direct Connect 環境における VPC 接続設計
既存の構築済み Direct Connect を利用して、外部サービスへアクセスする要件がありました。
また、接続元は単一の VPC に限らず、複数の VPC からの接続が必要であり、将来的に接続 VPC が増加する可能性も考慮する必要がありました。
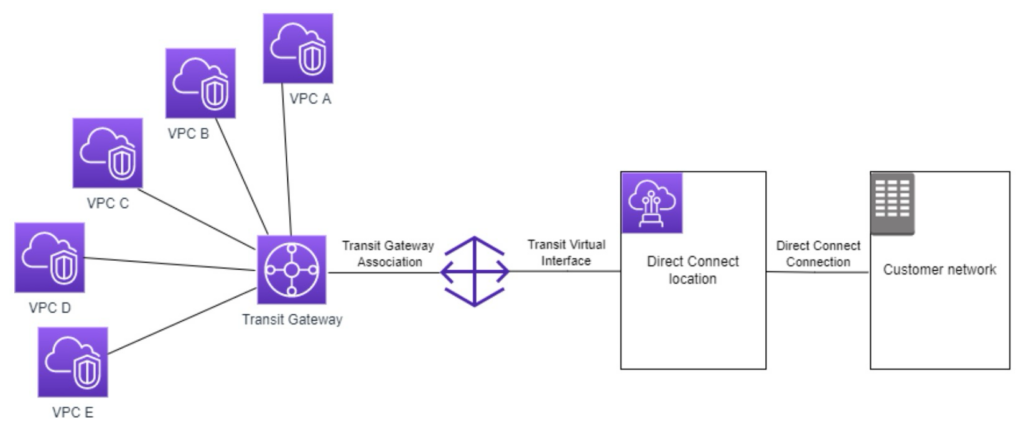
画像引用元:AWS Transit Gateway の Direct Connect ゲートウェイへの Transit Gateway アタッチメント
上記は AWS 推奨構成の1つである Transit Gateway + Direct Connect Gateway 経由での接続構成です。
構成図だけ見ると何と楽しそうなタスクでしょう。
しかし、ここからが苦難の道の始まりでした。
以下、Direct Connect 関連の用語を簡潔に補足します。
Direct Connect(DX)概要:
オンプレミスと AWS を 専用線で直接接続するサービスです。
インターネットを経由せず、安定した低遅延通信を実現します。Virtual Private Gateway(VGW)概要:
単一の VPC と Direct Connect/Site-to-Site VPN を接続するためのゲートウェイです。
Direct Connect Gateway(DXGW)概要:1本の Direct Connect 回線を 複数の VPC(VGW)に集約接続するためのゲートウェイです。
VPC 間通信はできませんが、オンプレミスとの接続先を柔軟に拡張できます。
Transit Gateway(TGW)概要:VPC や VPN、Direct Connect を ハブ&スポーク型で接続する中継ゲートウェイです。
推移的ルーティングが可能で、VPC間通信や大規模ネットワーク集約に適します。
Direct Connect Gateway 構成検討
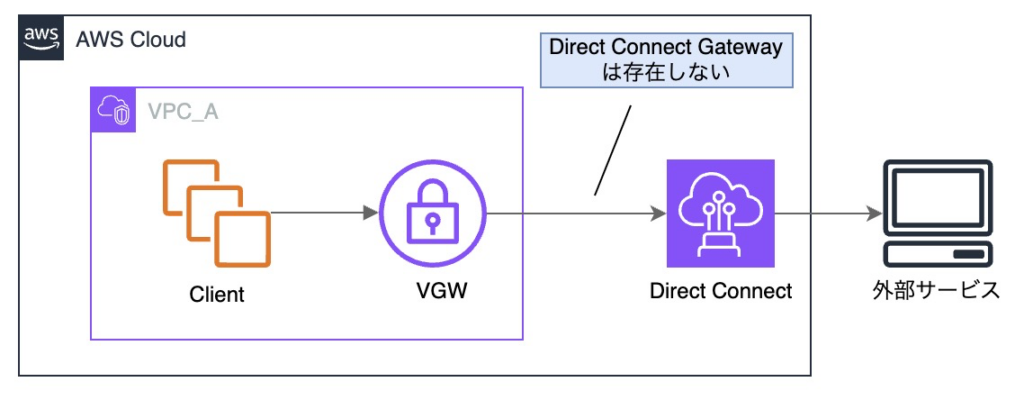
※ Direct Connect の先にはオンプレミス側ルータ / 外部ネットワークが存在します
現在 Direct Connect を新規構築する場合は、Direct Connect Gateway(以下 DXGW)も合わせて構築することが推奨されています。
ただし、上記の構成図のように今回の対象となる Direct Connect は、DXGW が存在しない構成でした。
構築当時は、単一VPC への接続を前提としていることもあり、「Virtual Private Gateway(VGW)→ DIrect Connect の直接接続」が一般的な構成パターンだったようです。
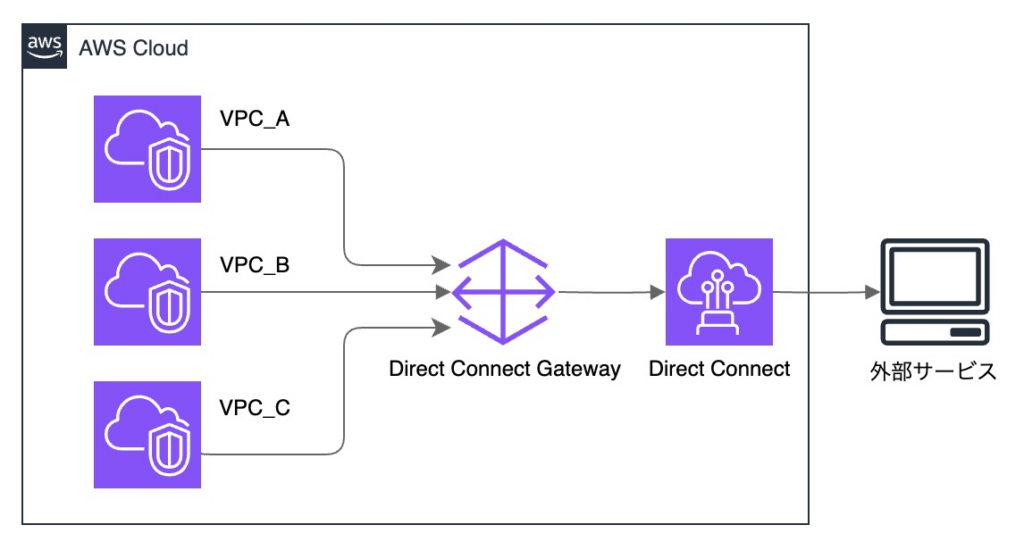
上記のように Direct Connect の前段に Direct Connect Gateway(DXGW)を配置することで、
接続VPCの増加にも柔軟に対応可能なため、今回の要件を満たすことが可能です。
ちなみに、一定のコストが発生しますが、Transit Gateway を DXGW の前段に構成することで、
VPC 間通信も可能になるため、ネットワーク構成の変更に対する柔軟性がはさらに向上します。
しかし、構成検討中に新たな制約が発生しました。
外部サービス側では接続元 IP アドレスの CIDR が制限されており、既存の Direct Connect が接続されている VPC の CIDR のみが許可対象であることが判明。
また、DXGW を利用するためには Direct Connect 管理アカウント側での設定作業が必要となり、関係者との調整が必須です。
これらの制約により、調整事項が多岐に渡ることが判明し、DXGW を用いた構成は残念ながら見送る判断としました。
VPC ピアリング接続の制約
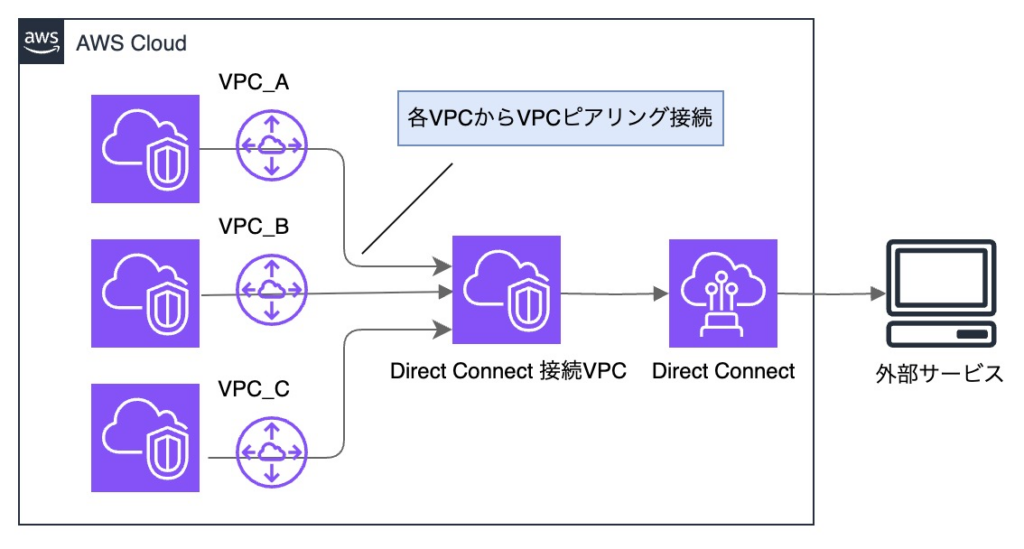
制約により、他の VPC は、既存の Direct Connect が接続されている VPC 経由での構成を目指します。
Transit Gateway を使用したくなりますが、既にVPC ピアリング済みの VPC もあり、
構成変更はリスクとなるため、各 VPC から VPC ピアリング接続する方針としました。
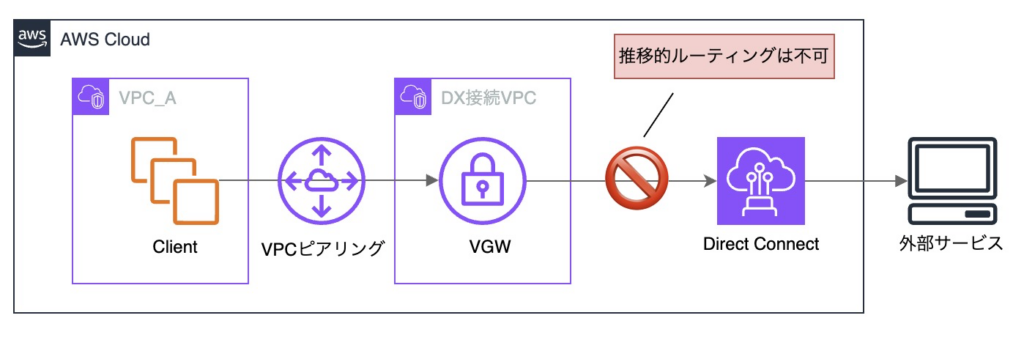
ただし、VPCピアリング接続の重要な制約として、推移的ルーティングができないことが挙げられます。
上記の構成では、推移的ルーティングに該当し、通信はできません。
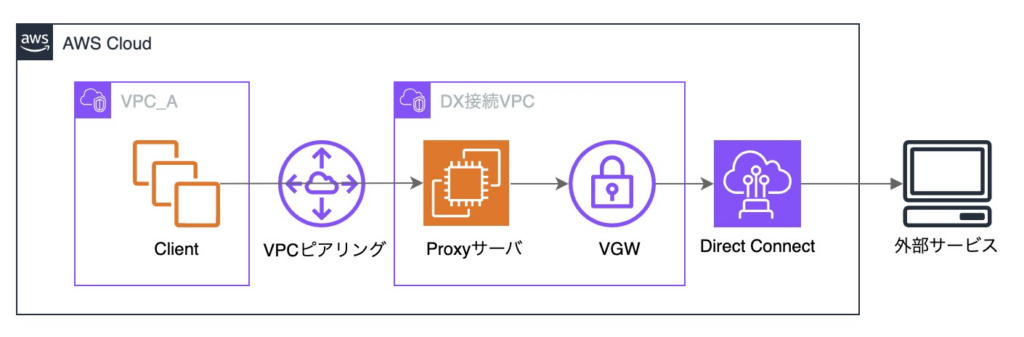
最終的に、プロキシサーバを用いて外部サービスへアクセスする構成を採用しました。
プロキシサーバはアプリケーションレイヤ(L7)で通信を終端し、クライアントからのリクエストを受けた後、新たな通信として外部サービスへ接続します。
この方式では、推移的ルーティングには該当せず、VPC ピアリングの制約を回避して通信が可能となります。
VPCピアリング、ルートテーブル、セキュリティグループ、プロキシサーバ設定を順次進め、
結果として、curl に -k オプションを付与し、証明書検証を無効化した状態で疎通確認が取れました。
プロキシ方式における証明書適用方針
ここまでたどり着くにも長い道のりでした。
しかし、証明書検証の無効化を許容するわけにもいきません。
証明書について調査を行い、適用方針について整理しました。
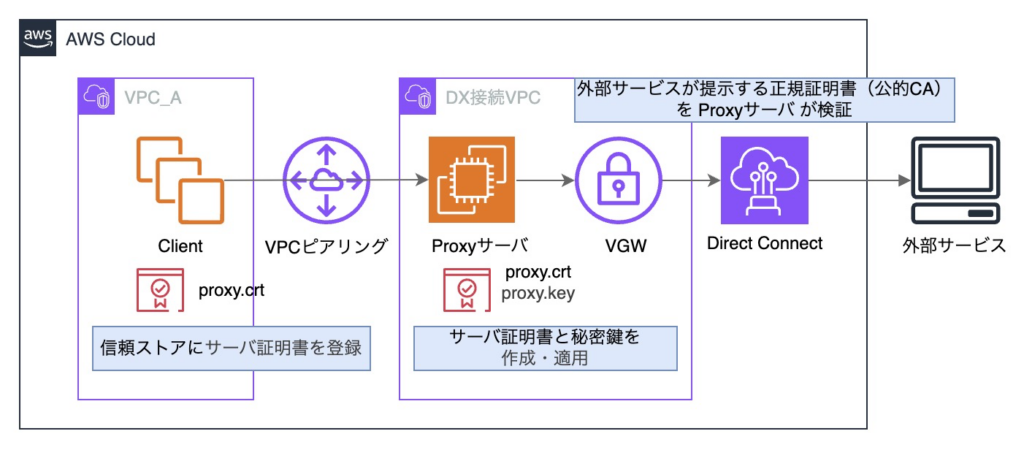
まず、外部サービスとの通信において、正規の証明書が必要となるのは、外部通信を実際に行うプロキシサーバのみです。
クライアントであるAPPサーバは外部サービスと直接通信しないため、正規の証明書を適用するメリットはありません。
次に、APP サーバとプロキシサーバ間の内部通信について検討しました。
この通信における選択肢は以下の2つです。
- アプリ側で証明書検証を無視する
- インフラ側(OSレベル)で証明書を信頼させる
アプリ側と協議して、セキュリティや保守性の観点から、今回はインフラ側で対応することにしました。
プロキシサーバで使用する自己署名証明書を、APPサーバ側で適用するという手法があります。
自己署名証明書は CA による署名がないためデフォルトでは信頼されません。
一方、APPサーバの信頼ストアに登録すれば、「信頼された証明書」として扱わせることができます。
セキュリティの観点では注意が必要ですが、内部通信に限定されているため、
今回のケースでは許容可能と判断しました。
上記対応により、証明書検証を無効化することなく、正規の証明書検証を維持したまま内部通信を行うことができました。
以上を踏まえ、最終的に以下のような設定を各VPCで適用しました。
▼CPからの学び
Direct Connect 構成は個人で再現できないので、さすがにCPでも扱っていません。笑
ただ、こちらのタスクの着手はCP入会前の時期だったため、課題を通して複雑な構成を扱った後であれば手応えは違っていたと思います。
今だったらメンバーも増えてきたので経験者がいるかもしれません。変化球のタスクが来たら気軽に Slack に投稿してみるのも良さそうです。
▼感想
いやーこのタスクは手探り続きでマジでむずかったです。
Direct Connect に触れられるチャンス?最高じゃん!と意気込んだものの、DX管理アカウントに入れるわけでもなく、検討した構成もことごとく潰されました。
DXGW や Transit Gateway 使えない制約はガチで詰んだかと思いましたし、推移的ルーティングの回避やプロキシサーバ、証明書もハマるポイントが多くて、有識者からアドバイスをもらいながら、泥臭くやってました。
総合力が試されるタスクでしたが、非常に学びも多かったです。達成感半端ない。
5. 環境変数の IaC 管理改善
Parameter Store に登録された環境変数が膨大(1万個〜)なケースについてです。
Terraform の一般的な管理方法 aws_ssm_parameter リソースで管理すると、
terraform plan / apply 実行に 1環境 5分〜10分 ほどかかる状況でした。
この実行時間は、パラメータ数に比例して増加するため、IaC 運用において大きなボトルネックとなっていました。
そこで、Terraform による 宣言的なリソース管理をあえて行わず、「JSON ファイルの状態を apply 時に同期する方式」へ変更しました。
具体的には、null_resource を使用して JSON ファイルの変更のみをトリガーとして検知し、Terraform 管理外の CLI / スクリプトを apply 時に実行する構成としています。
null_resource 概要:
null_resourceは、Terraform が実リソースを管理しないまま、トリガーの変化を検知し、Terraform 管理外の CLI / API / スクリプトを実行できるリソースです。
サンプルファイルを示しながら説明します。
・モジュール側での定義ファイル
モジュール側では、主にマイクロサービス単位で null_resource ブロックを定義しています。
null_resource では、指定した JSON ファイルに変更があった場合のみ処理を実行します。
この方式では、Terraform の destroy 処理に削除を委ねることなく、apply 時の同期処理のみで「追加・更新・削除」を完結させています。
resource "null_resource" "xxx_parameter" {
for_each = fileexists("${local.path}/xxxxx.json")
? jsondecode(file("${local.path}/xxxxx.json"))
: {}
triggers = {
parameter_value = each.value
}
# 追加・更新
provisioner "local-exec" {
command = <<EOT
aws ssm put-parameter --name "${each.key}" --value "${each.value}" --overwrite
EOT
}
# 削除
provisioner "local-exec" {
when = destroy
command = <<EOT
aws ssm delete-parameter --name "${each.key}"
EOT
}
}
JSONファイルの変更内容と Terraform の挙動の対応関係は、以下の通りです。
| 変更内容 | Terraform が検知する差分 | 起因箇所 | null_resource の挙動 | local-exec の実行 |
|---|---|---|---|---|
| JSON ファイルが存在しない | for_each = {} | fileexists() | null_resource 自体が作成されない | 実行されない |
| キー追加 | for_each の key が増加 | for_each | 新規 null_resource が作成される | 実行される |
| キー削除 | for_each の key が減少 | for_each | 該当 null_resource が削除される | destroy 側で実行される |
| 値変更 | triggers の値が変更 | triggers | null_resource が replace される | 再実行される |
| 変更なし | 差分なし | ― | 変更なし | 実行されない |
・環境側の指定ファイルのサンプル xxxxx.json
環境側では、主にマイクロサービス単位で JSONファイルを定義しています。
こちらに記載した key / value が、指定のパスに環境変数として登録されます。
{
"key1": "value1",
"key2": "value2",
"key3": "value3",
}以上の仕組みにより、xxxxx.json の内容変更がトリガーになり、
terraform apply 時に null_resource が再作成されて、local-exec が再実行されます。
これによって、環境変数の追加・削除・更新があった場合にのみ、指定ファイルを読み込む方式になり、環境変数における terraform plan / apply 実行が、5分〜10分 → 数秒 に短縮されました。
なお、機密性の高い環境変数は Secrets Manager へ登録しており、セキュリティ面を考慮し、Terraform 管理の対象外としています。
補足:
Terraform公式としては、null_resource を推奨していません。
null_resource は、Terraform の宣言的なリソース管理と相性が悪く、冪等性や差分管理が保証されないため、最終手段の位置付けです。
今回のケースにおいてはデメリットよりもメリットが圧倒的に勝ると判断し、採用しています。
なお、null_resource の後継として terraform_data というリソースが提供されているようです。
▼CPからの学び
今回はセキュリティ面と既存の本番運用を考慮して見送りましたが、
S3 に .env を配置して、environmentFiles で S3 オブジェクトキーを指定する手法は、効率化の観点で良いアイデアでした。
現場の背景に合わせて対応するために、手札をこれからも増やしていきたいです。
▼感想
Parameter Store の管理は正規の aws_ssm_parameter による管理が推奨されていますが、実行速度に影響が出やすいです。
とんでもない量の環境変数は長いことストレスの温床となっていましたが、ここで Terraform の実行速度が改善できたのは大きく、確実に勝利は近づいています。
メンバーも日々改善案やツールを考案してくれて、アイデアを見るのが楽しいです。
一般的な推奨設定がイマイチでも、工夫次第で効率化できることを実践できて良かったです!
6. タスク定義の管理改善
開発側とインフラ側で責務を完全に分離することで、運用効率が犠牲になることがあります。
先ほど記載した環境変数の管理と合わせて課題となっていたのは、タスク定義の管理でした。
高頻度でブランチごとにタスク定義(taskdef.json)の更新を行う必要があり、
修正・対応工数が増えてしまうという課題がありました。
そこで、次のステップで改善を進めました。
1. S3 にタスク定義を集約 → CI/CD で取得
2. Makefile 活用
S3 にタスク定義を集約 → CI/CD で取得
主な改善方法は以下の通りです。
① タスク定義の S3 管理
タスク定義格納用のS3バケットに、<環境>/<用途> 単位でディレクトリを作成しました。
ロールバックできるようバージョニングを有効化しています。
例:ディレクトリ構造
.
├── dev
│ ├── auth-service
│ │ └── taskdef.json
│ ├── content-service
│ │ └── taskdef.json
│ ├── secure-service
│ │ └── taskdef.json
│ └── ...
└── stg
├── auth-service
│ └── taskdef.json
├── content-service
│ └── taskdef.json
├── secure-service
│ └── taskdef.json
└── ...② CI/CD による環境情報の付与
CodeBuild にて、環境および用途(サービス名)を環境変数として定義しました。
これにより、ビルド実行時のタスク定義が一意に指定されます。
例:CodeBuild の環境変数
ENV=dev
SERVICE_NAME=auth-service
③ buildspec.yaml でのタスク定義取得
buildspec.yaml 内で②で指定した環境変数を参照し、S3 上に配置された該当の taskdef.json を取得します。
例:buildspec.yaml(抜粋)
phases:
build:
commands:
- echo "Fetch task definition"
- aws s3 cp \
s3://example-taskdef-bucket/${ENV}/${SERVICE_NAME}/taskdef.json \
taskdef.json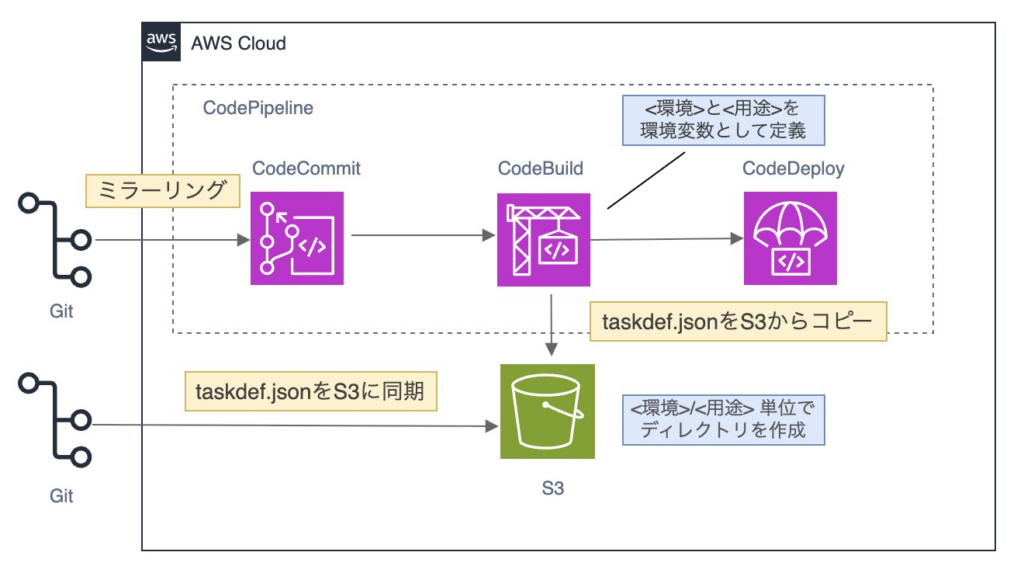
S3でバージョニング設定はしたものの、運用体験としてはtaskdef.jsonのバックアップ止まりの印象が拭えません。
不具合発生時に差分をすぐに追うことができず、Git管理は必須でした。
ただし、開発側とインフラ側のGitレポジトリは互いに独立しており、互いにアクセス権限がありません。
修正対応が必要になった場合、履歴を追いづらいという課題がありました。
そこで、インフラでGit管理しているタスク定義を更新後にS3に同期するという手段を考案しました。
Makefile 活用
タスク定義更新手順を以下のように定めました。
①バックアップ取得
②タスク定義更新
③タスク定義整形
④差分確認
⑤S3 同期対象確認
⑥S3 同期
しかし、すべて手動で行うのは非効率です。
そこで作業効率化のため Makefile を利用しました。
Makefile 概要:
複数のコマンドや処理手順を「ターゲット」として定義し、決められた名前で実行できる仕組みです。
主にビルドやデプロイ、運用作業の自動化・標準化に使われます。
Makefile やスクリプトを整備しながら、以下のように手順を作成しました。
| コマンド | 概要 | 備考 |
|---|---|---|
| make copy env=XXX | 対象環境の taskdef.json をバックアップ用ディレクトリにコピー | バックアップ取得。初回作業時や変更前に必ず実行する |
| (手動編集) | 対象サブディレクトリ配下の taskdef.json を修正 | 環境差分・設定変更を実施 |
| make fmt env=XXX | taskdef.json を整形 | キー順・配列順を統一 |
| make diff env=XXX | バックアップと更新後ファイルの差分を確認 | 証跡取得を兼ねる |
| make sync env=XXX dryrun=true | S3同期対象をドライランで確認 | 実際にアップロードはされない |
| make sync env=XXX | 差分のある taskdef.json のみ S3 に同期する | 変更分のみ反映 |
上記のように Makefile を使用し、makeコマンド1つで、複雑なコマンドやスクリプトが実行できるため、
タスク定義の更新が効率的かつ正確に行えるようになり、不具合発生時の調査も容易になりました。
なお、CI/CD 化も検討しましたが、アプリ側の依頼対応を前提とした運用体制を考慮し、現在のフローに落ち着きました。
▼CPからの学び
Makefile について、Docker や DB マイグレーション等での活用をCPの課題で学んでおり、
効率化や自動化の仕組みなども各課題に散りばめられていたこともあり、今回の着想に至ることができました。
なお、CPで ecspresso を使用したECS 管理方法についても学びましたが、
作業工数とコミュニケーションコストの兼ね合いで、今回は導入に至りませんでした。
より効率的な方法を提案できる土台はあるので、導入できる機会があれば取り入れてみたいです。
▼感想
タスク定義の管理方法は様々で、こいつに苦しめられてる現場もそこそこあるんじゃないでしょうか。
特に規模が大きくなるにつれて課題が顕在化してくるケースもあり、手札は多いに越したことはありません。
ecspresso 導入についても虎視眈々と狙っていきます。
Makefile も最高ですね。作業効率が格段に上がるので、タスク定義に限らず、運用改善の手法としてこれからもアイデアを出していきたいです!
7. AWS 環境差異の設定統一
環境数の増加に伴い、環境ごとの設定差異が蓄積し、
開発・テストに影響が出る問題が発生していました。
環境差異が発生した主な要因は、以下のようなものが挙げられます。
- 構築手順の違い(GUIでの構築、Terraform構築、モジュールを利用したTerraform構築)
- 構築時期の違い(AWS側のデフォルト値の変更影響)
- 一部構成のみが異なる環境が存在し、設定の差異が生じている
- 一時的な変更依頼の対応後、そのままになってしまった設定
この問題を解決するため、環境の設定統一を行うことになりました。
環境差異の把握と設定統一アプローチ
今回のケースでは、環境数・リソース数が膨大にあり、本来の環境特有設定などもあるため、全量比較は現実的ではありません。
そこで以下の手順で差分確認と設定統一を進めました。
①差分確認対象となるAWSサービスの選定
②基準となる環境を2つ選定
③差分出力スクリプトを作成し、差分を可視化
④差分を精査し、意図しない差分の洗い出し
⑤適切な設定値を確認し、全環境へ適用
①差分確認対象となるAWSサービスの選定
全AWSサービスを対象とすると調査・確認工数が足りません。
よって、影響範囲が広く、不具合に直結しやすいサービスを優先的に選定しました。
② 基準となる環境を2つ選定
環境差異が発生した背景を踏まえ、特に差分が生じやすいと考えられる 2 環境を基準として選定しました。
本番環境は、可用性やセキュリティなどの特有の設定が多いため、指定しませんでした。
③差分出力スクリプトを作成し、差分を出力
ここが最大のポイントです。
Terraform のコードや tfstate の差分を取得しても、実際の AWS 環境と完全に一致しないケースがあります。
よって、AWSの実環境を正とし、aws describe コマンドの結果を直接比較する方針を採用しました。
地道な確認は避けられませんが、スクリプトを作成することで作業を大幅に効率化できました。
スクリプトの概要は以下の通りです。
- AWS プロファイルとリソース名を指定
- 各サービスごとに aws describe の結果を取得
- スクリプトで差分を抽出・出力
- main_diff.sh から対象サービスを切り替え可能
ECSの差分出力スクリプトの例を記載します。
#!/bin/bash
# 環境変数
export AWS_PROFILE_1="dev1"
export AWS_PROFILE_2="dev2"
# ECS クラスターとサービスの配列
CLUSTERS_1=(
"sample-dev1-ecs-cluster"
)
CLUSTERS_2=(
"sample-dev2-ecs-cluster"
)
SERVICES_1=(
"sample-dev1-ecs-service"
)
SERVICES_2=(
"sample-dev2-ecs-service"
)
# 出力ファイル
OUTPUT_DIR="./result"
OUTPUT_FILE="$OUTPUT_DIR/output_diff_ecs.txt"
: > "$OUTPUT_FILE"
# 差分出力関数
output_diff_section() {
local section="$1"
local diff_content="$2"
{
echo "## $section"
echo ""
echo "$diff_content"
echo ""
echo ""
echo ""
} >> "$OUTPUT_FILE"
}
# --- 比較処理 ---
# 全てのクラスターとサービスを比較
for i in "${!CLUSTERS_1[@]}"; do
CLUSTER_1="${CLUSTERS_1[$i]}"
CLUSTER_2="${CLUSTERS_2[$i]}"
SERVICE_1="${SERVICES_1[$i]}"
SERVICE_2="${SERVICES_2[$i]}"
# 1. ECS Cluster
cluster_diff=$(diff -us <(aws ecs describe-clusters --profile "$AWS_PROFILE_1" --clusters "$CLUSTER_1" --include ATTACHMENTS SETTINGS CONFIGURATIONS STATISTICS TAGS) \
<(aws ecs describe-clusters --profile "$AWS_PROFILE_2" --clusters "$CLUSTER_2" --include ATTACHMENTS SETTINGS CONFIGURATIONS STATISTICS TAGS))
output_diff_section "ECS Cluster ($CLUSTER_1 vs $CLUSTER_2)" "$cluster_diff"
# 2. ECS Service(events 除外)
service_diff_clean=$(diff -us <(aws ecs describe-services --profile "$AWS_PROFILE_1" --cluster "$CLUSTER_1" --services "$SERVICE_1" | jq 'del(.services[].events)') \
<(aws ecs describe-services --profile "$AWS_PROFILE_2" --cluster "$CLUSTER_2" --services "$SERVICE_2" | jq 'del(.services[].events)'))
output_diff_section "ECS Service ($SERVICE_1 vs $SERVICE_2)" "$service_diff_clean"
done
# 完了メッセージ
echo "### Completed ###"
echo "Output file: $(realpath "$OUTPUT_FILE")"工夫した点は以下の通りです。
- 配列を使用し、複数リソースを同時に差分比較可能にする
- 差分結果をコピペ可能な形式で出力(証跡として利用)
- eventsなど、冗長で比較不要な項目は除外
差分比較スクリプトの作成・調整には時間がかかりましたが、汎用性の高いスクリプトが作成できたと思います。
④差分を精査し、意図しない差分の洗い出し
差分が生じた設定について、1つずつ精査しました。
各サービスの設定内容をある程度理解していないと、意図されたものかの判断が難しくなります。
重要度や影響度を見極めながら、「意図しない差分」と判断したものを洗い出しました。
⑤適切な設定値を確認し、全環境へ適用
設定適用にあたっては、以下の点を考慮しました。
- ダウンタイムの有無
- 通信断のリスク
- セキュリティ影響
- 即時反映可能か、再起動が必要か
影響範囲を整理し、段階的に全環境へ適用していきました。
以上が、差分確認と設定統一の手順となります。
差分取得スクリプトの応用例
作成した差分取得スクリプトは、今回以外にも以下の用途で活用しています。
・環境差分のチェック
今回のケースです。環境差分のチェックに適したスクリプトです。
・環境コピー後の精度担保
STG 環境を terraform import → 本番環境へ apply
といったケースでは、コード上は同一に見えても、実環境の設定が完全一致しているとは限りません。
差分を取得することで、「何が同じで、何が違うのか」を即座に把握できます。
・同一環境内での構築精度担保
同じ環境内でも、既存リソースを参考に新規リソースを構築するケースがあります。
差分を取得することで、構築精度の担保や想定外の差分検知が可能になります。
例えば、既存のバッチサーバを参考に新規バッチサーバを構築する場合、
差分を取得することで、構成の抜け漏れや想定外の差分を検知できます。
・レビュー / 証跡用途
aws describe の結果をそのまま貼り付けると、情報量が多く、レビューで流し見されがちです。
差分という形で要点を抽出することで、レビュー効率や妥当性が向上しました。
▼CPからの学び
差分比較スクリプトはオリジナルですが、CPのTerraform Applyコースでも活用しながら実践的に改良を重ねることができました。課題を進める中でスクリプトが他でも通用するかを検証でき、レビューもしていただいたため、たいへんありがたい機会でした。これからも汎用性を重視してスクリプトを磨き上げていきたいです。
▼感想
今回は環境差異を修正する意図で差分比較スクリプトを作成しましたが、応用も効いて嬉しかったです。
有識者がいない(あるいは鬼忙しい)現場だとレビュー文化がなかったり、形式だけの場合もあると思います。
だけど、失敗したら怒られる。もうやってられるかと半分怒りを込めながら徹底的にセルフレビューしてやろうと思いついたアイデアが差分比較による精度の担保です。転んでもただでは起きません。
ここまでやると例え失敗したとしても、「自分以外の誰がやったとしても失敗していただろう」と(心の中で)開き直れるようになりました。おかげさまでメンタルの健康は保たれています。
8. 既存環境の Terraform による IaC・モジュール設計
2024年は、開発環境の構築を兼ねて Terraform 導入を1から進めました。
2025年は、Terraform未経験者が Terraform 運用を行うことを見据えて、既存環境の Terraform による IaC・モジュール設計のタスクに取り組みました。
現状、Terraform を適切に扱える人が少なく、Terraform は限られたメンバーのみが使用することが前提でした。
よって、最も重視した点は、未経験者や新規参入者でも理解・修正できる認知負荷の低い設計です。
しかし、既に モジュールを使用して構築されたサービスもあるため、モジュールを前提として IaC 化していく必要もありました。
ここでは、設計の特徴や構造を4点に絞って記載します。
ディレクトリ全体構造
ディレクトリの全体構造は、以下の通りです。
.
├── common/ # 環境共通リソース
├── envs/ # 環境固有設定
│ ├── dev/ # dev 環境固有設定
│ ├── stg/ # stg 環境固有設定
│ └── prd/ # prd 環境固有設定
└── modules/ # module ディレクトリ
ディレクトリやファイル構造については、一般的に普及しており、直感的にも理解しやすい型を採用しました。
また、環境共通で使われるリソースは、common ディレクトリに配置することで、所在の明確化と柔軟性を高めました。
環境ディレクトリのルートは、以下の通りです。
envs/dev/
├── parameters # 環境変数用ディレクトリ
├── backend.tf # バックエンド設定(環境ごとのtfstate設定)
├── data.tf # データ参照(既存リソースの参照)
├── main.tf # モジュール呼び出しとリソース定義
├── locals.tf # 環境固有のlocal変数定義
├── providers.tf # プロバイダー設定
└── versions.tf # バージョン設定こちらも基本的には一般的な構造だと思います。
以下、2点補足します。
・parameters
「5. 環境変数の IaC 管理改善」でも言及した 環境変数設定用の JSON ファイルとバックアップが格納されています。
・data.tf
既存リソースの参照用ファイルです。id 指定や arn 指定のパラメータは可読性が落ちるため、data.tf に記載した data ブロックからリソース参照する方針としました。
全てをモジュール化しない
モジュール化には明確なメリットがある一方、過度な抽象化は認知負荷と保守コストを高めます。
そのため、以下を全て満たすサービス・リソースのみモジュール化することにしました。
- リソース構成が各環境でほぼ同じ
- 命名規則・タグが統一されている
- 差異を変数で容易に吸収できる
- 変数が過剰にならない
- 変更頻度が低い
この判断を間違えるとモジュール化は非常に難航します。
差異を変数で吸収すれば問題ないだろうとモジュール化を進めていったところ、抽象度がどんどん上がり、認知負荷も工数も高くなった苦い経験があります。
そこから「迷ったらモジュール化をしない」方針を固く誓いました。
例えば、本番環境は特有の差異が多いため、一切モジュールを使用しない判断をしています。
余談ですが、作業工数に対して IaC 化のメリットが薄いものは、IaC 化しない方針も重要です。
全てを IaC 化することが正義ではありません。
AWSサービス単位の一層フラット構造
modules 配下は、AWS サービスごとの 一層フラット構造 を採用しています。
modules/
├── alb/
├── ec2/
├── ecs/
├── rds/
├── s3/
├── security_group/
...
この構造の主なメリットは、以下の通りです。
- AWSサービスとディレクトリが 1 対 1 で対応するため、所在が明確で初見でも迷わない
- 新規追加や修正時に置き場所で迷うことがなく、意思決定コストが低い
- 入出力が最小限のモジュール構成となり、差分が明確でレビューしやすい
- サービス単位で module を分離できるため、部品として再利用しやすく横展開が容易
一方、主なデメリットは、以下の通りです。
- サービス間の依存関係を環境側で明示的に繋ぐ必要がある
- 依存関係を考慮した apply 順序の判断が必要になる
- 複数サービスが常にセットで動く構成では、単体モジュールの組み合わせが煩雑になりやすい
デメリット軽減のため、必要に応じて以下を許容するものとしました。
- 薄い統合モジュールを用意する(例:modules/sftp)
- 環境側で直接AWSリソースを定義する (例:stg/sftp.tf)
例外を作るリスクもありますが、デメリット軽減に繋がるため、バランスを考えた設計になり得ると思います。
変数化の基準
変数化は、運用と保守性を最優先に判断しています。
- 汎用性を持たせず、対象のプロジェクトに閉じる
- 環境側のパラメータ肥大化を避ける
- モジュール側の編集頻度を極力減らし、長期的な保守性を高める
上記方針を前提として、変数化の要否を判断します。
以下のいずれかに該当する場合は変数化します。
- 環境ごとに値の差異が存在する、または将来的に差異が発生する可能性が高い
- 既存環境との差異を吸収する必要がある
- バージョンアップや構成変更など、将来的に値を変更する可能性がある
以下に該当する場合はモジュール内で固定し、変数化しません。
- 全環境で値が共通であり、差異が発生しない
- 将来的に変更される可能性が低い
- プロジェクトの標準値として扱える
上記基準を定めることで、編集頻度や変更範囲が制限されるため、運用と保守性の向上に繋がると考えます。
▼CPからの学び
・リソースのimport → module 化 を一気に行う手法を獲得
ディレクトリおよびモジュール構成の型が明確で、爆速で IaC 化対応ができました。
以前の約3倍のスピードでコード化が完了し、クオリティも格段に高くなりました。
・設計における判断基準の明確化
設計における各基準とメリット/デメリットが明確だったので、チーム内の意見を取り入れながら有意義な議論をすることができました。判断基準は独学では絶対にたどり着かなかった領域なので、個人的にCPの学びの中で最も感動した点です。
▼感想
Terraform は、プロジェクトの背景や規模、チームのレベルに応じて、 柔軟に IaC を設計していく力が求められます。AIに完全代替されるのはまだ先だと思います。自由度が高いからこそ、設計の段階で有識者がリードしていくことが重要だと思いました。
この章は、本気で書くと10章分ぐらいのボリュームになりそうだったので割愛しました。Terraform は本当に面白いです。美しい設計を追求していきたいです。
9. AWS コスト削減 6選
コスト削減の肝は、削減のインパクトが大きいものから対応することです。
ここでは、特に削減効果の高かった6点について記載します。
※一部自分が主導でないタスクも含まれますが、チームタスクとして対応させていただきました。
- 不要リソースの削除
- インスタンスタイプ変更
- ECS スケジュールアクションによるコスト最適化
- Savings Plan および RI の購入
- ストレージのライフサイクル設計
- Fluent Bit(FireLens)による ECS ログ転送先の分離
9.1 不要リソースの削除
放置された不要リソースほど無駄なコストはありません。
CloudWatchのメトリクスを確認し、3ヶ月以上使われていないと思われるリソースは削除検討としました。
また、負荷試験サーバなど環境共通で使い回せるリソースがあれば、1つに統一すべく吟味を行いました。
あわせて、停止不可リソースにおいて使用しない期間の「一時削除」運用の可否も検討しました。
しばらく使用しない前提であれば、利用するタイミングで再構築を行うことでコストを下げられるためです。
結論として、今後少しでも使用される可能性があるリソースは、残す方針としています。
例えば、ElastiCache や Transfer Family は、再作成を行う場合にエンドポイントが変更される可能性があります。
IaCでコードをApplyしてもまったく同じように構築されるわけではなく、仮に再構築することになった場合は、依存関係のあるリソースにおいて環境変数などの調整工数が発生します。
停止不可のリソースの「一時削除」運用の可否は、コストと作業工数とのトレードオフとなります。
アプリ側との協議の結果、残すことにしました。
9.2 インスタンスタイプ変更
次に、インスタンスタイプ変更の検討を行いました。
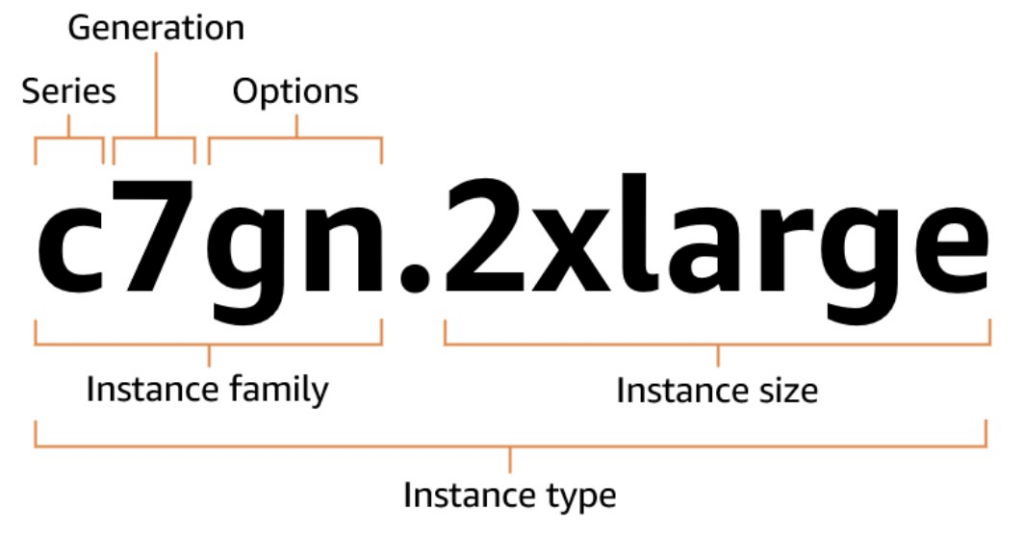
画像引用元:Amazon EC2 インスタンスタイプの命名規則
https://docs.aws.amazon.com/ja_jp/ec2/latest/instancetypes/instance-type-names.html
EC2 のインスタンスタイプという表現を使っていますが、RDS や ElastiCache などでも基本的な考え方は同じです。
インスタンスタイプは、以下 4つの要素の組み合わせで構成されています。
- Series(シリーズ)
- Generation(世代)
- Options(オプション)
- Instance size(インスタンスサイズ)
インスタンスタイプの変更を検討する際は、それぞれの観点を分解して考えます。
(ルビコン塾生ならおなじみの内容かもしれません)
・Series(シリーズ)
よく使用されるシリーズは、以下のあたりかと思います。
M:汎用
R:メモリ最適化
C:コンピューティング最適化
T:バースト可能パフォーマンス
特に、汎用用途として M系 を選択しておくことが多い印象です。
一方、CPU 使用率やメモリ使用率などのメトリクスを確認し、より適したシリーズが存在する場合は変更を検討します。
例えば、シリーズを M系 から R系 に 変更し、インスタンスサイズを1つ下げるといった変更でコスト削減が可能です。
T 系 は低コストで利用できる一方、一定以上の CPU 負荷が継続すると CPUクレジットを消費します。
t2の場合、CPUクレジットを使い切るとCPU性能はベースラインまで制限されます。
一方、t3以降の世代では「Unlimitedモード」がデフォルトとなり、クレジットを使い切ってもCPU性能自体は制限されませんが、ベースラインを超えたCPU使用分について追加課金が発生します。
よって、性能変動やコスト予測の難しさから、本番環境では、T系 の採用は限定的となるケースが多いです。
一方、開発環境では、アプリ側と協議し、「クレジット消費後のベースライン性能」を前提として、変更検討をしました。
・Generation(世代)
一般的に、世代が新しいほど性能が向上し、コストも抑えられる傾向があります。
ただし、OSやミドルウェアの互換性などを調査する必要があり、コスト削減としては検討対象外としました。
・Options(オプション)
主に検討対象となるのは g(Graviton)オプション です。
Arm64(Graviton)を利用することで、x86_64(Intel / AMD 系)インスタンスと比較して、約 2 割程度 コストが低下する傾向があります。
よって、新規構築の場合は、アプリ側と協議し、互換性の懸念がなければ Graviton で構築することが多いです。
一方、既存環境の場合は、互換性の観点でリスクを考慮する必要があるため、コスト削減としては検討対象外としました。
・Instance size(インスタンスサイズ)
micro / small / medium / large / xlarge / 2xlarge …
といった形で、サイズが 1段階上がるごとに コストが概ね倍増します。
性能も概ね倍増しますが、必ずしも倍とは限らないため AWS 公式情報の確認が必要です。
コスト削減の検討においては、インスタンスサイズの見直しが最も効果的かつ実施しやすい手法だと思います。
補足:EBS ボリュームの世代(gp2 → gp3)について
余談ですが、EC2 や RDS(※Aurora を除く)で使用される EBS ボリュームの世代が gp2 のままになっているケースがあります。
gp2 から gp3 への変更は オンラインで実施可能であり、性能面の向上に加えて、約 2 割程度 のコスト削減効果が見込めます。
よって、特別な理由がなければ gp3 へアップグレードしておくことが推奨されます。
コスト削減施策の一環として、インスタンスタイプ変更と合わせて確認しておくと効果的です。
9.3 ECS スケジュールアクションによるコスト最適化
ECS はタスク数を柔軟に制御できますが、Auto Scaling のみでは意図したタイミング・粒度での制御は難しいです。
そこで活用できるのが、スケジュールアクションです。
例えば、利用者が比較的少ない深夜の時間帯にタスク数を減らすことでコスト削減を図ることができます。
CloudWatchメトリクスを確認して、実際の利用状況に基づいてスケジュールアクションを設計しました。
ポイントは、負荷特性に応じてタスク数の制御方法を使い分けた点です。
スケジュールアクションは、cron 式などで最小タスク数、最大タスク数を指定できます。
今回は「最小タスク数の変更」で制御していますが、タスク数の挙動は以下のようになりました。
上昇時:不足分のタスクが一瞬で一括して増加
下降時:タスクが 1 つずつ順番に減少
よって、以下の4パターンでタスク数の制御を行うことにしました。
- 利用者数が緩やかに上昇する時間帯は、スケジュールアクションを複数設定し、段階的なスケールアウト
- 利用者数が緩やかに下降する時間帯は、スケジュールアクションを単体もしくは複数設定し、段階的なスケールイン
- 利用者数が短時間で大きく上昇する時間帯は、スケジュールアクションで一括変更
- 利用者数が短時間で大きく下降する時間帯は、EventBridge Scheduler で希望するタスクを変更
実態とは異なりますが、イメージは以下の通りです。
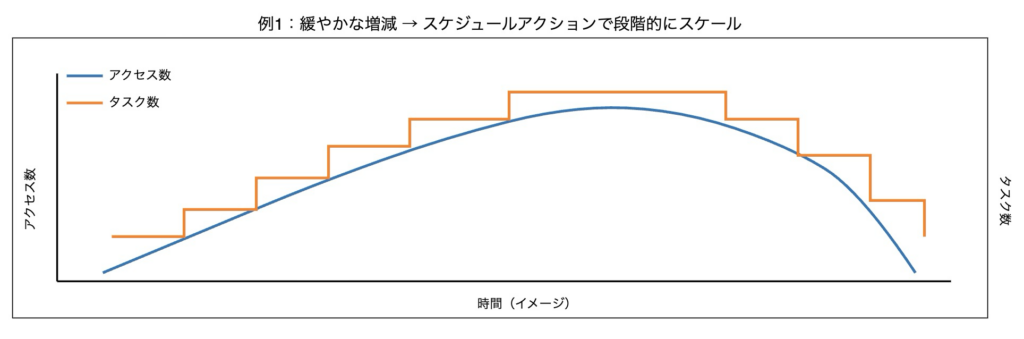
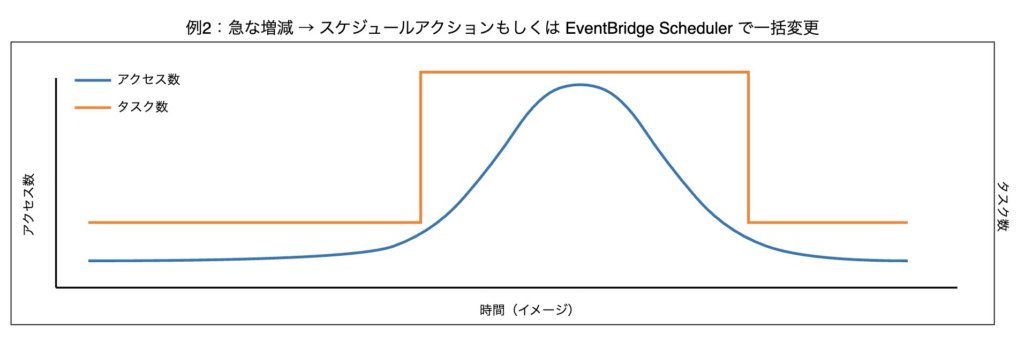
これらを併用することで、負荷に応じたタスク数を起動できるため、コスト最適化に繋がります。
また、スケジュールアクションによってタスク数を減らしている状態でも、想定外の負荷が発生した場合に Auto Scaling が正常に動作するか検証しました。
結果として、負荷に応じて問題なくスケールアウトすることを確認しています。
9.4 Savings Plans および RI の購入
AWSには、Savings Plans と RI (リザーブドインスタンス)という一定期間の利用を前提にコミットすることで、オンデマンド料金よりも低コストで利用できる割引制度があります。
購入方法によって割引率が異なるため、購入内容の検討を行いました。
なお、契約期間は1年と3年がありますが、リスクを考慮して1年での購入を前提としています。
また、契約期間中は未使用であっても料金が発生し、返金もできないため、今後1年以内に廃止・移行される可能性がなく、利用状況が安定しているリソースに限定して適用する方針としました。
さらに、コスト削減 9.1 〜 9.3 の内容と依存関係があることにも留意する必要があります。
Savings Plans と RI の対応サービス
Savings Plans と RI ではそれぞれ対応サービスが決まっています。
以下、代表的なサービスの対応を表にまとめました。
| サービス | Savings Plans | RI |
|---|---|---|
| EC2 | ○ | △ |
| ECS(Fargate) | ○ | × |
| Lambda | ○ | × |
| RDS / Aurora | △ | ○ |
| ElastiCache | △ | ○ |
| OpenSearch | × | ○ |
| Redshift | × | ○ |
○:対応・制約少 △:対応・制約多 ×:未対応
現在 EC2 において RI を選定するメリットは非常に限定的なので、Savings Plans で検討します。
RDS / Aurora および ElastiCache は 2025年12月に Database Savings Plans が対応しました。
ただし、割引率は RI より低く、RDS / Aurora は、一部のインスタンスタイプのみ対応、ElastiCache は、Valkeyのみ対応といった制約があるため、従来通り RI を選定するケースの方が多いと思います。
購入検討にの詳細については、EC2、ECS(Fargate)、RDSの3点に絞って記載します。
EC2 (Savings Plans)
Saving Plans による EC2 の購入方法は、2パターンあります。
①Compute Savings Plans
→最も無難な購入方法です。インスタンスファミリーが変更可能なうえ、ECS や Lambda にも割引を適用できます。
②EC2 Instance Savings Plans
→インスタンスファミリーは変更できず、ECS や Lambda にも適用できませんが、①より割引率が高いメリットがあります。
一方、①は ECS のスケールに応じて割引の適用先を自動的に切り替えられるメリットがあるため、変更の可能性が限りなく低いリソースに限り②を適用しました。
ECS (Savings Plans)
Savings Plans は、時間単位でコミットメントを行う割引モデルです。
よって、ECS(Fargate)では、タスク数の増減を前提とした設計が必要になります。
例えば、日中帯の通常時のタスク数を基準にコミット額を設定した場合、
深夜帯などタスク数が少ない時間帯では、コミット額を消費しきれず割引が無駄になります。
一方、深夜帯のタスク数を基準にコミット額を設定した場合、
日中帯のタスク数増加分についてはオンデマンド料金が適用され、割引効果が限定的になります。
したがって、タスク数の変動幅を考慮してコミット額の調整が必要になってきます。
そこで、Savings Plans の 購入アナライザー(過去の利用実績を基に最適なコミット額を算出する機能) を参考にしつつ、一時的なスパイクや例外的な増減を調整して、購入額を検討しました。
RDS(RI)
RI は、特定のインスタンスタイプ(クラス)を予約購入する割引モデルです。
起動・停止関係なく課金されるため、夜間停止するようなリソース適しません。
インスタンスファミリーは変更できませんが、RDS RI は一部のDBエンジンを除き、インスタンスサイズに柔軟性があることがポイントです。
RDS RI の割引適用可否は、購入時のインスタンスサイズそのものではなく、インスタンスサイズごとに定められた「正規化係数」によって決定されます。
以下は、RDS におけるインスタンスサイズと正規化係数の対応例です。
| インスタンスサイズ | 正規化係数 |
|---|---|
| .micro | 0.5 |
| .small | 1 |
| .medium | 2 |
| .large | 4 |
| .xlarge | 8 |
| .2xlarge | 16 |
例えば、同一インスタンスファミリーであれば、スケールアップを行った場合でも、購入した RI の正規化係数分までは割引が適用されます。
よって、将来的にインスタンスサイズを変更する可能性があるリソースでも、利用状況が安定していれば RI の購入は十分に検討可能です。
なお、制約はあるものの、RDS だけではなく、ElastiCache も2024年10月に RI のサイズの柔軟性に対応しています。
9.5 ストレージのライフサイクル設計
ストレージ料金はチリツモで増えていくので定期的に見直しが必要です。
ライフサイクルを適切に設計することで、コスト削減だけでなく、見直し作業の工数も削減できます。
ここでのライフサイクルの見直し対象は、S3、EFS、ECR、CloudWatch Logs の4点とし、ポイントを絞って記載します。
なお、バックアップのライフサイクルも重要ですが、コスト削減のタスクとして調整していないため、ここでは割愛します。
・S3:可視化+自動最適化
ライフサイクルといえば、最初に思い浮かぶのが S3 です。
ただし、バケットごとにライフサイクルルールの有無や設定内容がばらついていたりするので、見直しは意外と大変です。
そこで、Storage Lens を利用することで、バケット全体の使用状況を可視化でき、削減余地の洗い出しを行いました。
また、モニタリング料金は若干発生しますが、アクセス頻度の予測が難しいデータに対しては、S3 Intelligent-Tiering を活用することで、運用負荷を増やさずにコスト最適化が可能です。
・EFS:IA自動移行
EFS は、一定期間アクセスされていないファイルを自動的に IA(およびアーカイブ)へ移行でき、運用工数を増やさずにコスト削減が可能です。
東京リージョンにおいては、標準ストレージから IA ストレージへの移行で、料金は約 1/16 程度 となり、驚異の削減率です。
| ストレージクラス | 用途概要 | 料金(GB/月) |
|---|---|---|
| スタンダード(SSD) | 頻繁にアクセスされるアクティブデータ | USD 0.36 |
| 低頻度アクセス(IA) | 四半期に数回程度アクセスされるデータ | USD 0.02 |
| アーカイブ | 年に数回しかアクセスされない長期保存データ | USD 0.01 |
取り出しに料金は発生しますが、低頻度であることが前提であり、レイテンシもミリ秒未満から数十ミリ秒への変化です。
頻繁にアクセスされた場合は、スタンダードに自動で戻せるオプションもあるため安心です。
・ECR:世代管理
ECR はライフサイクルを設定していないと、イメージが蓄積され続け、気づかないうちにコストが増加しがちです。
また、サービスごとにイメージの Push 頻度は異なるため、ライフサイクルは、保存期間よりも「◯世代保持」といった世代ベースの設定の方が実運用に適しているケースが多いと判断しています。
地味にイメージの軽量化もコストに効いてくる点でした。
・CloudWatch Logs:保持期間+出力の見直し
各リソース作成時に自動生成される CloudWatch Logs は無期限保管となっており、そのまま放置されているケースも多いかと思います。ログの保持期間を適切に設定した上で、必要に応じて IA への移行も検討したいところです。
また、CloudWatch Logs は保管料金よりもログの取り込み(出力)料金の方が支配的になるケースが多いため、出力量そのものの見直しも必須です。出力の見直しは次項で扱います。
9.6 Fluent Bit(FireLens)による ECS ログ転送先の分離
CloudWatch Logs のログ収集(取り込み)コストは、AWS の中でも凶悪な料金体系だと思います。
以下、公式の料金表から抜粋しました。
| 区分 | 内容 | 料金 |
|---|---|---|
| ログ収集(Standard) | 通常ログの取り込み | $0.76 / GB / 月 |
| ログ収集(Infrequent Access) | 低頻度参照ログの取り込み | $0.38 / GB / 月 |
| ログ保存(Archive) | アーカイブ保存 | $0.033 / GB / 月 |
| クエリ(Logs Insights) | ログ検索・分析 | $0.0076 / GB |
Amazon CloudWatch Pricing よりCloudWatch Logs 料金(東京リージョン)を抜粋
ログ収集(Standard)の料金は、$0.76 / GB / 月 と非常に高く、特に対策をしていない場合は、費用が高騰しやすいです。
そこで、特にコストが高騰していた ECS を対象に対策を検討しました。
まず、最も効果的な対策は、不要なログの除外設定 および ログレベルの変更です。
ただし、アプリ側の調査が難航したため、インフラ側で別途対応を進めることになりました。
具体的には、重要度の高いログのみを CloudWatch Logs に出力させ、それ以外のログは S3 に出力させる構成に変更しました。
実装としては、ECS FireLens の log router コンテナとして Fluent Bit を利用し、ログの転送先を分離しています。
最終的に以下の構成としました。
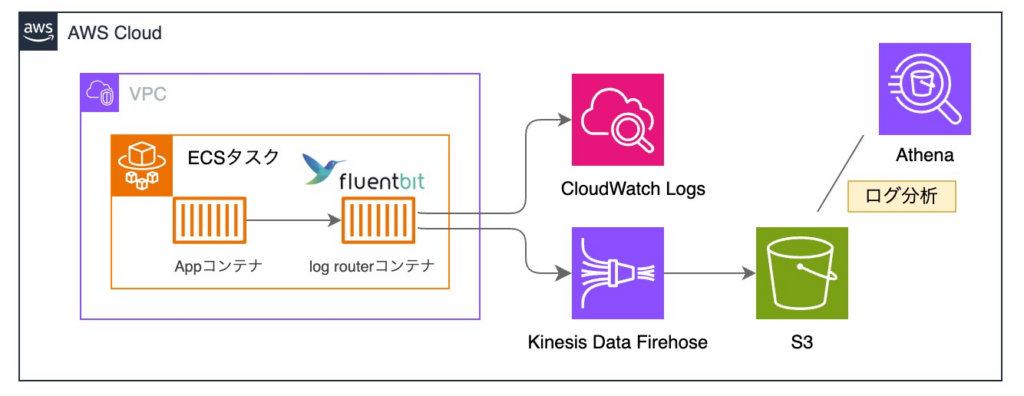
結果として 60% 程度 のコスト削減を実現しています。
以下、構成の補足となります。
・Fluent Bit サイドカー構成
Fluentd と比較して軽量であり、ECS Fargate とも相性が良い Fluent Bit を採用しました。
ECS FireLens を用いたサイドカー構成とすることで、ログ転送処理をアプリケーションから分離しています。
・Fluent Bit 設定ファイル管理
Fluent Bit の設定ファイルは S3 に保存し、ログルーターコンテナから参照する構成としています。
これによって、イメージの再ビルドを行わずに設定変更が可能となり、運用の柔軟性を重視しました。
・Kinesis Data Firehose 導入
コストは増加するものの、ログ欠損防止を目的として Kinesis Data Firehose を採用しています。
検証の結果、直接 S3 へ転送する構成では欠損が発生する可能性があることが判明しており、バッファリングおよび再試行機構を持つ Firehose を経由することで、安定性を優先しています。
・S3 ログ確認方法
ログの出力先を S3 に分離したことにより、ログ確認方法が大きく変更されました。
S3 上のログはファイル単位での確認には向かないため、Athena を用いた検索・分析を前提としています。
▼CPからの学び
コスト削減はCPで学んだことが活かせる場面が多くありました。
CPでは最初のAWS基礎コースから、NATインスタンス、Fargate Spot、リソース停止・起動スクリプト、EventBridge スケジューラ導入など、AWS個人学習者としても活用できる優れた手法をガンガン学べます。
一方、AWS道場コースにあるコスト削減道場は、非常に実践的なコスト削減を学べる内容です。
削減効果が高い手法を一気に増やせるだけでなく、自分が今まで取り組んできたコスト削減の深掘りをすることもできました。Cost Explorer の活用方法、Kinesis Firehose 連携、Savings Plans / RI の判断基準などは特に参考にさせていただきました。
▼感想
コスト削減してて考えること第1位
「これだけコスト削減したんだから給料に反映してくれ!!!!」
あると思います。
実際にコスト削減されて数字やグラフが動くのを見るのは楽しいです。
コスト削減は手札が無数にある領域なので、どのカードから切っていくかが重要ですね。
ケチな人に向いてると思います!(自分のことです)
おわりに
ここまで読んでくださり本当にありがとうございました。
気づいたら35000字を超えるボリュームになってました。
執筆には想定の5倍ぐらい時間がかかりました。
見積もりが甘いなんてレベルじゃありません。
技術記事を書くってめちゃくちゃ大変ですね。
だからこそ普段から書いてる方は本当に尊敬するし、いつも助けられてるなって思います。
書く側になって初めてわかることもあるし、アウトプットすることで経験が整理されて最高に良い機会でした。
ちなみに構成図はAI生成だとこだわりたい部分に手が届かなかったので、公式引用以外は全て drawio で自作しました。
CPの drawio のレクチャー課題がなかったら完全に挫折していたと思います。
知れば知るほど技術は奥深いですね。
実現可能か不安になる場面もありましたが、今年もなんとか乗り切ることができました。
1年前と比べると設計の精度も向上し、成長できたと思います。
長い目で見ればエンジニア人生は始まったばかりだし、自分はまだまだ足を止めません。
恵まれた環境で学べていることに感謝しつつ、2026年も頑張ろうと思います!